3. Formulario Muestreo#
3.1. Tipos de muestreo.#
Nº de muestras posibles según el tipo de muestreo
Con reposición |
Sin reposición |
|
|---|---|---|
Si orden |
\(VR_{N,n}=N^{n}\) |
\(V_{N,n}=\binom{N}{n}\cdot n!\) |
No orden |
\(CR_{N,n}=\binom{N+n-1}{n}\) |
\(C_{N,n}=\binom{N}{n}\) |
(*) Todas las muestras son equiprobables, salvo en el caso de No importar orden y con reposición.
3.2. Intervalos de Confianza con normalidad#
3.2.1. Se puede suponer hay insesgadez#
3.2.2. No hay distribución normal#
Se utiliza la t-student: \(\left[\hat{\theta}-t_{n-1,\alpha/2}\sigma(\hat{\theta})\ ;\ \hat{\theta}+t_{n-1,\alpha/2}\sigma(\hat{\theta})\right]\)
Se puede utilizar también la desigualdad de Tchebichev: \(\left[\hat{\theta}-\frac{\sigma(\hat{\theta})}{\sqrt{\alpha}}\ ;\ \hat{\theta}+\frac{\sigma(\hat{\theta})}{\sqrt{\alpha}}\right]\)
3.2.3. El estimador es sesgado#
3.3. Muestreo aleatorio simple.#
3.4. Muestreo sin reposición.#
\(V(\hat{X})=N^{2}(1-f)\frac{S^{2}}{n}\) |
\(V(\hat{\overline{X}})=(1-f)\frac{S^{2}}{n}\) |
|---|---|
\(V(\hat{A})=\frac{N^{3}}{N-1}\frac{1}{n}(1-f)PQ\) |
\(V(\hat{P})=\frac{N}{N-1}\frac{1}{n}(1-f)PQ\) |
Para el caso de proporciones, se tiene: \(S^{2}=\frac{N}{N-1}PQ\) y \(\hat{S}^{2}=\frac{n}{n-1}\hat{P}\hat{Q}\)
3.4.1. Estimación de varianzas.#
\(\hat{V}(\hat{X})=N^{2}(1-f)\frac{\hat{S}^{2}}{n}\) |
\(\hat{V}(\hat{\overline{X}})=(1-f)\frac{\hat{S}^{2}}{n}\) |
|---|---|
\(\hat{V}(\hat{A})=N^{2}(1-f)\frac{1}{n-1}\hat{P}\hat{Q}\) |
\(\hat{V}(\hat{P})=(1-f)\frac{1}{n-1}\hat{P}\hat{Q}\) |
3.4.2. Tamaño de la muestra.#
3.4.2.1. Para un error de muestreo dado.#
-Para la media
-Para el total
- Para la proporción.
-Para total de clase.
3.4.2.2. Para un error relativo de muestreo dado.#
-Para la media:
-Para total:
-Proporción y total de clase:
3.5. Muestreo con reposición.#
Los estimadores insesgados son los mismos que para el caso de muestreo sin reposición.
\(V(\hat{X})=N^{2}\frac{\sigma^{2}}{n}\) |
\(V(\hat{\overline{X}})=\frac{\sigma^{2}}{n}\) |
|---|---|
\(V(\hat{A})=N^{2}\frac{PQ}{n}\) |
\(V(\hat{P})=\frac{PQ}{n}\) |
3.5.1. Estimación de varianzas.#
\(\hat{V}(\hat{X})=N^{2}\frac{\hat{S}^{2}}{n}\) |
\(\hat{V}(\hat{\overline{X}})=\frac{\hat{S}^{2}}{n}\) |
|---|---|
\(\hat{V}(\hat{A})=N^{2}\frac{1}{n-1}\hat{P}\hat{Q}\) |
\(\hat{V}(\hat{P})=\frac{1}{n-1}\hat{P}\hat{Q}\) |
3.5.2. Tamaño de la muestra.#
3.5.2.1. Para un error de muestreo dado.\(e=\sigma(\hat{\theta}).\)#
media |
total |
proproción |
total clase |
|---|---|---|---|
\(n=\frac{\sigma^{2}}{e^{2}}\) |
\(n=\frac{\sigma^{2}N^{2}}{e^{2}}\) |
\(n=\frac{PQ}{e^{2}}\) |
\(n=\frac{N^{2}PQ}{e^{2}}\) |
3.5.2.2. Error relativo de muestreo dado. \(e_{r}=CV(\hat{\theta})\)#
media |
total |
proporción |
total clase |
|---|---|---|---|
\(n=\frac{\left(\sigma/\overline{X}\right)^{2}}{e_{r}^{2}}\) |
\(n=\frac{\left(\sigma/\overline{X}\right)^{2}}{e_{r}^{2}}\) |
\(n=\frac{Q}{Pe_{r}^{2}}\) |
\(n=\frac{Q}{Pe_{r}^{2}}\) |
3.5.2.3. Error de muestreo y coeficientes de confianza dados. \(e_{\alpha}=z_{\alpha/2}\sigma(\hat{\theta})\)#
media |
total |
proporción |
total clase |
|---|---|---|---|
\(n=\frac{z_{\alpha/2}^{2}\sigma^{2}}{e_{\alpha}^{2}}\) |
\(n=\frac{z_{\alpha/2}^{2}\sigma^{2}N^{2}}{e_{\alpha}^{2}}\) |
\(n=\frac{z_{\alpha/2}^{2}PQ}{e_{\alpha}^{2}}\) |
\(n=\frac{z_{\alpha/2}^{2}PQN^{2}}{e_{\alpha}^{2}}\) |
3.5.2.4. Error relativo de muestreo y coeficiente de confianza dados.\(e_{r\alpha}=z_{\alpha/2}CV(\hat{\theta})\)#
media |
total |
proporción |
total clase |
|---|---|---|---|
\(n=\frac{z_{\alpha/2}^{2}\left(\sigma/\overline{X}\right)^{2}}{e_{r\alpha}^{2}}\) |
\(n=\frac{z_{\alpha/2}^{2}\left(\sigma/\overline{X}\right)^{2}}{e_{r\alpha}^{2}}\) |
\(n=\frac{z_{\alpha/2}^{2}Q}{e_{r\alpha}^{2}P}\) |
\(n=\frac{z_{\alpha/2}^{2}Q}{e_{r\alpha}^{2}P}\) |
3.6. Notas.#
El muestreo sin reposición es más preciso que el muestreo con reposición.
Con el muestreo sin reposición se necesita menos tamaño de muestra para cometer el mismo error que en el caso del muestreo con reposición.
4. Muestreo estratificado.#
4.1. Estimadores#
4.2. Muestreo estratificado sin reposición.#
4.2.1. Varianzas.#
\(V(\hat{X}_{st})=\sum_{h}N_{h}^{2}(1-f_{h})\frac{S_{h}^{2}}{n_{h}}\) |
\(V(\overline{x}_{st})=\sum_{h}W_{h}^{2}(1-f_{h})\frac{S_{h}^{2}}{n_{h}}\) |
|---|---|
\(V(\hat{A}_{st})=\sum N_{h}^{2}(1-f_{h})\frac{N_{h}}{N_{h}-1}\frac{P_{h}Q_{h}}{n_{h}}\) |
\(V(\hat{P}_{st})=\sum_{h}W_{h}^{2}(1-f_{h})\frac{N_{h}}{N_{h}-1}\frac{P_{h}Q_{h}}{n_{h}}\) |
4.2.2. Estimación de varianzas.#
\(\hat{V}(\hat{X}_{st})=\sum_{h}N_{h}^{2}(1-f_{h})\frac{\hat{S}{}_{h}^{2}}{n_{h}}\) |
\(\hat{V}(\overline{x}_{st})=\sum_{h}W_{h}^{2}(1-f_{h})\frac{\hat{S}{}_{h}^{2}}{n_{h}}\) |
|---|---|
\(\hat{V}(\hat{A}_{st})=\sum_{h}N_{h}^{2}(1-f_{h})\frac{\hat{P}_{h}\hat{Q}_{h}}{n_{h}-1}\) |
\(\hat{V}(\hat{P}_{st})=\sum_{h}W_{h}^{2}(1-f_{h})\frac{\hat{P}_{h}\hat{Q}_{h}}{n_{h}-1}\) |
4.2.3. Afijación de la muestra.#
4.2.3.1. Afijación uniforme.#
\(V(\hat{X}_{st})=\sum_{h}N_{h}^{2}(1-\frac{k}{N_{h}})\frac{S_{h}^{2}}{k}\) |
\(V(\overline{x}_{st})=\sum_{h}W_{h}^{2}(1-\frac{k}{N_{h}})\frac{S_{h}^{2}}{k}\) |
|---|---|
\(V(\hat{A}_{st})=\sum_{h}N_{h}^{2}(1-\frac{k}{N_{h}})\frac{N_{h}}{N_{h}-1}\frac{P_{h}Q_{h}}{k}\) |
\(V(\hat{P}_{st})=\sum_{h}W_{h}^{2}(1-\frac{k}{N_{h}})\frac{P_{h}Q_{h}}{k}\) |
4.2.3.2. Afijación proporcional.#
\(V(\hat{X}_{st})=\frac{1-k}{k}\sum_{h}N_{h}S_{h}^{2}\) |
\(V(\overline{x}_{st})=\frac{1-k}{n}\sum_{h}W_{h}S_{h}^{2}\) |
|---|---|
\(V(\hat{A}_{st})=\frac{1-k}{k}\sum_{h}\frac{N_{h}^{2}}{N_{h}-1}P_{h}Q_{h}\) |
\(V(\hat{P}_{st})=\frac{(1-k)}{k}\sum_{h}\frac{N_{h}^{2}/N}{N_{h}-1}P_{h}Q_{h}\) |
4.2.3.3. afijación de mínima varianza ( afijación de Neyman).#
\(V(\hat{X}_{st})=\frac{1}{n}\left(\sum_{h=1}^{L}N_{h}S_{h}\right)^{2}-\frac{1}{N}\sum_{h=1}^{L}N_{h}S_{h}^{2}\) |
\(V(\overline{x}_{st})=\frac{1}{n}\left(\sum_{h=1}^{L}W_{h}S_{h}\right)^{2}-\frac{1}{N}\sum_{h=1}^{L}W_{h}S_{h}^{2}\) |
|---|
Para obtener la afijación o la expresión de la varianza mínima para la proporción y el total de clase, en las fórmulas anteriores, se sustituye \(S_{h}^{2}\) por \(P_{h}Q_{h}N_{h}/(N_{h}-1)\)
4.2.3.4. Afijación óptima.#
Para obtener la afijación o la expresión de la varianza mínima para la proporción y el total de clase, en las fórmulas anteriores, se sustituye
\(S_{h}^{2}\) por \(P_{h}Q_{h}N_{h}/(N_{h}-1)\)
4.2.4. Tamaño de la muestra.#
4.2.4.1. Error de muestreo dado \(e=\sigma(\hat{\theta})\).#
4.2.4.1.1. Media, total, proporción y total de clase con afijación proporcional.#
- Para la media.
-Para el total:
Los tamaños de la muestra en los casos de la proporción y total de clase, se calculan sustituyendo \(S_{h}^{2}\) por \(\frac{N_{h}}{N_{h}-1}P_{h}Q_{h}\) en las fórmulas del tamaño de la muestra para la estimación de la media y el total respectivamente.
4.2.4.1.2. Media, total, proporción y total de clase con afijación de mínima varianza.#
-Para la media:
-Para el total:
Los tamaños de la muestra en los casos de la proporción y total de clase, se calculan sustituyendo \(S_{h}^{2}\) por \(\frac{N_{h}}{N_{h}-1}P_{h}Q_{h}\) en las fórmulas del tamaño de la muestra para la estimación de la media y el total respectivamente.
4.2.4.2. Error de muestreo y coeficiente de confianza dados \(e_{\alpha}=z_{\alpha}\sigma(\hat{\theta}).\)#
4.2.4.2.1. Media, total, proporción y total de clase con afijación proporcional.#
- Para la media.
-Para el total.
Los tamaños de la muestra en los casos de la proporción y total de clase, se calculan sustituyendo \(S_{h}^{2}\) por \(\frac{N_{h}}{N_{h}-1}P_{h}Q_{h}\) en las fórmulas del tamaño de la muestra para la estimación de la media y el total respectivamente.
4.2.4.2.2. Media, total, proporción y total de clase con afijación de mínima varianza.#
-Para la media:
-Para el total:
Los tamaños de la muestra en los casos de la proporción y total de clase, se calculan sustituyendo \(S_{h}^{2}\) por \(\frac{N_{h}}{N_{h}-1}P_{h}Q_{h}\) en las fórmulas del tamaño de la muestra para la estimación de la media y el total respectivamente.
4.2.4.3. Tamaño de la muestra sin especificar el tipo de afijación.#
-Para la media:
-para el total
4.3. Muestreo estratificado con reposición.#
Los estimadores lineales insesgados del total, media, proporción y total de clase son los mismos que en el caso sin reposición.
4.3.1. Varianzas de los estimadores.#
\(V(\hat{X}_{st})=\sum_{h}N_{h}^{2}\frac{\sigma_{h}^{2}}{n_{h}}\) |
\(V(\overline{x}_{st})=\sum_{h}W_{h}^{2}\frac{\sigma_{h}^{2}}{n_{h}}\) |
|---|---|
\(V(\hat{A}_{st})=\sum N_{h}^{2}\frac{P_{h}Q_{h}}{n_{h}}\) |
\(V(\hat{P}_{st})=\sum_{h}W_{h}^{2}\frac{P_{h}Q_{h}}{n_{h}}\) |
4.3.2. Estimación de varianzas.#
\(\hat{V}(\hat{X}_{st})=\sum_{h}N_{h}^{2}\frac{\hat{S}{}_{h}^{2}}{n_{h}}\) |
\(\hat{V}\overline{x}_{st})=\sum_{h}W_{h}^{2}\frac{\hat{S}{}_{h}^{2}}{n_{h}}\) |
|---|---|
\(\hat{V}(\hat{A}_{st})=\sum_{h}N_{h}^{2}\frac{\hat{P}_{h}\hat{Q}_{h}}{n_{h}-1}\) |
\(\hat{V}(\hat{P}_{st})=\sum_{h}W_{h}^{2}\frac{\hat{P}_{h}\hat{Q}_{h}}{n_{h}-1}\) |
4.3.3. Afijación uniforme.#
\(V(\hat{X}_{st})=\sum N_{h}^{2}\frac{\sigma_{h}^{2}}{k}\) |
\(V(\overline{x}_{st})=\sum_{h}W_{h}^{2}\frac{\sigma_{h}^{2}}{k}\) |
|---|---|
\(V(\hat{A}_{st})=\sum_{h}N_{h}^{2}\frac{P_{h}Q_{h}}{k}\) |
\(V(\hat{P}_{st})=\sum_{h}W_{h}^{2}\frac{P_{h}Q_{h}}{k}\) |
4.3.4. Afijación proporcional.#
\(V(\hat{X}_{st})=\frac{1}{k}\sum_{h}N_{h}\sigma_{h}^{2}\) |
\(V(\overline{x}_{st})=\frac{1}{n}\sum_{h}W_{h}\sigma_{h}^{2}\) |
|---|---|
\(V(\hat{A}_{st})=\frac{1}{k}\sum_{h}N_{h}P_{h}Q_{h}\) |
\(V(\hat{P}_{st})=\frac{1}{n}\sum_{h}W_{h}\frac{P_{h}Q_{h}}{k}\) |
4.3.5. Afijación de mínima varianza o de Neyman.#
media |
total |
|---|---|
\(n_{h}=n\frac{N_{h}\sigma_{h}}{\sum_{h}N_{h}\sigma_{h}}\) |
\(n_{h}=n\frac{W_{h}\sigma_{h}}{\sum_{h}W_{h}\sigma_{h}}\) |
\(V(\overline{X}_{st})=\frac{1}{n}\left(\sum_{h=1}^{L}W_{h}\sigma_{h}\right)^{2}\) |
\(V(\overline{X}_{st})=\frac{1}{n}\left(\sum_{h=1}^{L}N_{h}\sigma_{h}\right)^{2}\) |
Si se quiere esta afijación para la proporción y el total de clase, hay que sustituir \(\sigma_{h}\) en la expresión anterior por \(P_{h}Q_{h}\)
4.3.6. Afijación óptima#
media |
total |
|---|---|
\(n_{h}=n\frac{N_{h}\sigma_{h}/\sqrt{c_{h}}}{\sum_{h}(N_{h}\sigma_{h})/\sqrt{c_{h}}}\) |
\(n_{h}=n\frac{W_{h}\sigma_{h}/\sqrt{c_{h}}}{\sum_{h}(W_{h}\sigma_{h})/\sqrt{c_{h}}}\) |
\(V(\hat{\overline{X}}_{st})=\frac{1}{n}\left(\sum_{h=1}^{L}W_{h}\sigma_{h}/\sqrt{c_{h}}\left(\sum_{h=1}^{L}W_{h}\sigma_{h}\cdot\sqrt{c_{h}}\right)\right)\) |
\(V(\hat{X}_{st})=\frac{1}{n}\left(\sum_{h=1}^{L}N_{h}\sigma_{h}/\sqrt{c_{h}}\left(\sum_{h=1}^{L}N_{h}\sigma_{h}\cdot\sqrt{c_{h}}\right)\right)\)
Si se quiere esta afijación para la proporción y el total de clase, hay que sustituir \(\sigma_{h}\) en la expresión anterior por \(P_{h}Q_{h}\)
4.3.7. Tamaño de la muestra.#
a) Error de muestreo dado \(e=\sigma(\hat{\theta})\).
- Media, Total, proporción y total de clase con afijación proporcional.
- Para la media.
- Para el total.
Para el caso de la proporción y el total de la clase, se emplean las fórmulas anteriores sustituyendo \(\sigma_{h}^{2}\) por \(P_{h}Q_{h}\)
- Media, Total, proporción y total de clase con afijación de mínima varianza.
-Para la media:
-Para el total.
Para el caso de la proporción y el total de la clase, se emplean las fórmulas anteriores sustituyendo \(\sigma_{h}^{2}\) por \(P_{h}Q_{h}\)
b) Error de muestreo y coeficiente de confianza dados \(e_{\alpha}=z_{\alpha/2}\sigma(\hat{\theta})\).
- Media, Total, proporción y total de clase con afijación proporcional.
-Para la media.
-Para el total
Para el caso de la proporción y el total de la clase, se emplean las fórmulas anteriores sustituyendo \(\sigma_{h}^{2}\) por \(P_{h}Q_{h}\).
- Media, Total, proporción y total de clase con afijación de mínima varianza.
- para la media.
- Para el total.
5. Muestreo sistemático.#
Definiciones:
cuasivarianza muestral:\(S^{2}=\frac{1}{n-1}\sum_{i,j}\left(x_{ij}-\overline{X}\right)^{2}\)
cuasivarianza intermuestral: \(S_{bs}^{2}=\frac{1}{k-1}\sum_{i=1}^{n}\sum_{j=1}^{k}\left(\overline{x}_{j}-\overline{X}\right)^{2}\)
cuasivarianza intramuestral: \(S_{ws}^{2}=\frac{1}{N-k}\sum_{i=1}^{n}\sum_{j=1}^{k}\left(X_{ij}-\overline{X}\right)^{2}\)
Se verifica: \((N-1)S^{2}=(N-k)S_{ws}^{2}+(k-1)S_{bs}^{2}\)
5.1. Varianzas en función de \(S_{bs}^{2}\).#
- General (para el total)
- a partir de cuasivarianza intermuestral
\(V(\hat{\overline{X}})=(1-f)\frac{S_{bs}^{2}}{n}\) |
\(V(\hat{X})=N^{2}(1-f)\frac{S_{bs}^{2}}{n}\) |
|---|---|
\(V(\hat{P})=\frac{1}{N}\sum_{i=1}^{n}\sum_{j=1}^{k}\left(\hat{P}_{j}-P\right)^{2}\) |
\(V(\hat{A})=N\sum_{i=1}^{n}\sum_{j=1}^{k}\left(\hat{P}_{j}-P\right)^{2}\) |
- a partir de cuasivarianza intramuestral
\(V(\hat{\overline{X}})=\sigma^{2}-\frac{n-1}{n}S_{ws}^{2}\) |
\(V(\hat{X})=N(N-1)S^{2}-N(N-k)S_{ws}^{2}\) |
|---|---|
\(V(\hat{P})=PQ-\frac{1}{k}\sum_{j}^{k}\hat{P}_{j}\hat{Q}_{j}\) |
\(V(\hat{A})=N^{2}\left(PQ-\frac{1}{k}\sum_{j}^{k}\hat{P}_{j}\hat{Q}_{j}\right)\) |
5.2. Coeficiente de correlación intramuestral.#
Una medida de homogeneidad entre los elementos de una misma muestra sistemática es:
5.3. Muestreo estratificado vs sistemático.#
- cuasivarianza interestratal \(S_{bst}^{2}=\frac{1}{n-1}\sum_{i=1}^{n}\sum_{j=1}^{k}\left(\overline{X}_{i}-\overline{X}\right)^{2}\)
-cuasivarianza intraestratal: \(S_{wst}^{2}=\frac{1}{N-n}\sum_{i,j}\left(X_{ij}-\overline{X}\right)^{2}\)
\(\rho_{wst}\) es el coeficiente de correlación lineal entre las desviaciones de las medias de los estratos de todos los pares de valores que están en la misma muestra sistemática.
5.4. Estimación de la varianza.#
No hay método directo. Estudiamos los siguientes casos.
- \(\rho_{w}\) próximo a cero:
- \(\rho_{wst}\) próximo a cero.
- ninguno de los coeficientes de correlación anteriores están próximo a cero.
Se utilizaría método muestras interpenetrantes.
6. Métodos de estimación indirecta.#
6.1. Método de la razón#
En general el estimador \(\hat{R}\) es sesgado de \(R=\frac{\overline{X}}{\overline{Y}}\). Se tiene: \(B(\hat{R})=-\rho_{(\hat{R},\overline{y})}\sigma_{\hat{R}}Cv(\overline{y}).\text{\ensuremath{\hat{R}}}\) será insegado si:
\(\hat{R}\) e \(\overline{y}\) son incorreladas, ó
.- \(\left|\frac{B(\hat{R})}{\sigma_{\hat{R}}}\right|\le Cv(\overline{y})<0.1\)
Para conseguir que \(\hat{R}\) sea más o menos insesgado, se debe tomar n: \(n>\frac{100N\frac{S_{Y}^{2}}{\overline{y}^{2}}}{N+100\frac{S_{Y}^{2}}{\overline{y}^{2}}}\) (muestreo sin reposición). Para muestreo con reposición: \(n>100\frac{\sigma_{y}^{2}}{\overline{Y}^{2}}\)
- Si la recta de regresión de Y/X ( o X/Y) pasa por el origen de coordenadas entonces \(\hat{R}\) es insesgado.
6.1.1. Estimador de Hartley y Ross.#
Va a ser siempre insesgado de R. Se construye así:
6.1.2. Sesgo aproximado.#
valor |
estimación |
|
|---|---|---|
Muest. sin repos. |
\(B(\hat{R})=\frac{(1-f)}{n\overline{Y}^{2}}(RS_{Y}^{2}-S_{XY})\) |
\(\hat{B}(\hat{R})=\frac{(1-f)}{n\overline{Y}^{2}}(\hat{R}\hat{S}_{Y}^{2}-\hat{S}_{XY})\) |
Muest. con repos. |
\(B(\hat{R})=\frac{1}{n\overline{Y}^{2}}\left(R\sigma_{Y}^{2}-\sigma_{XY}\right)\) |
\(\hat{B}(\hat{R})=\frac{1}{n\overline{Y}^{2}}\left(\hat{R}\hat{S}_{Y}^{2}-\hat{S}_{XY}\right)\) |
6.1.3. Varianza aproximada.#
Muest. sin rep. (valor) |
\(V(\hat{R})=\frac{1-f}{\overline{Y}^{2}n(N-1)}\left[\sum_{1}^{N}X_{i}^{2}+R^{2}\sum_{1}^{N}Y_{i}^{2}-2R\sum_{1}^{N}X_{i}Y_{i}\right]\) |
|---|---|
Muest. sin rep. (esti.) |
\(\hat{V}(\hat{R})=\frac{1-f}{\overline{Y}^{2}n(n-1)}\left[\sum_{1}^{n}X_{i}^{2}+\hat{R}^{2}\sum_{1}^{n}Y_{i}^{2}-2\hat{R}\sum_{1}^{n}X_{i}Y_{i}\right]\) |
Muest. con rep. (valor) |
\(V(\hat{R})=\frac{1-f}{\overline{Y}^{2}nN}\left[\sum_{1}^{N}X_{i}^{2}+R^{2}\sum_{1}^{N}Y_{i}^{2}-2R\sum_{1}^{N}X_{i}Y_{i}\right]\) |
Muest. con rep. (esti.) |
\(\hat{V}(\hat{R})=\frac{1-f}{\overline{Y}^{2}n(n-1)}\left[\sum_{1}^{n}X_{i}^{2}+R^{2}\sum_{1}^{n}Y_{i}^{2}-2R\sum_{1}^{n}X_{i}Y_{i}\right]\) |
6.2. Estimación de parámetros.#
Total |
Media |
Proporción |
Total clase |
|---|---|---|---|
\(\hat{X}_{R}=\hat{R}\cdot Y\) |
\(\hat{\overline{X}_{R}}=\hat{R}\overline{Y}\) |
\(\hat{P}_{RX}=\hat{R}P_{Y}\) |
\(\hat{A}_{RX}=\hat{R}A_{Y}\) |
Estos estimadores son insesgados si lo es el estimador de la razón.
6.3. Varianzas de los estimadores.#
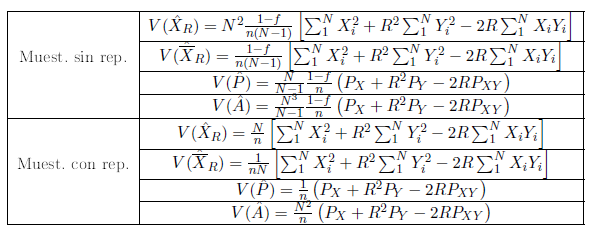
6.4. Estimación varianzas#
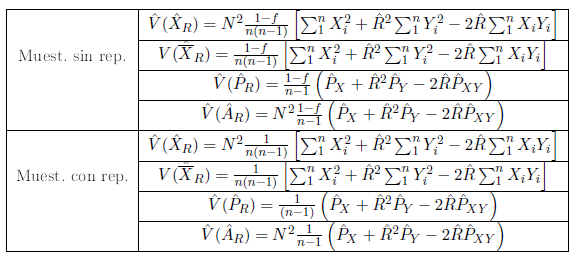
7. Muestreo por conglomerados.#
7.1. Conglomerados mismo tamaño sin submuestreo.#
\(\overline{M}\) Número de unidades elementales en el conglomerado. \(n\) : Número de conglomerado en la muestra. \(N\) número de conglorados en la población
7.1.1. Muestreo sin remplazamiento en primera etapa.#
\(\hat{X}=N\overline{M}\overline{\overline{x}}\qquad\hat{\overline{X}}=\overline{\overline{x}}\qquad\hat{P}=\frac{1}{n}\sum_{i=1}^{n}P_{i}\qquad\hat{A}=N\overline{M}\hat{P}\ con\ \overline{\overline{x}}=\frac{1}{n}\sum_{i=1}^{n}\overline{X}_{i}\)
\(V(\overline{\overline{x}})=(1-f)\frac{S_{b}^{2}}{n\overline{M}}\quad S_{b}^{2}=\frac{\sum_{i=1}^{N}\sum_{j=1}^{\overline{M}}\left(\overline{X}_{i}-\overline{X}\right)^{2}}{N-1};\ V(\hat{X})=N^{2}\overline{M}^{2}(1-f)\frac{S_{b}^{2}}{n\overline{M}}\)
\(V(\hat{P})=(1-f)\frac{\sum_{i=1}^{N}(P_{i}-P)^{2}}{n(N-1)};\ V(\hat{A})=N^{2}\overline{M}^{2}(1-f)\frac{\sum_{i=1}^{N}(P_{i}-P)^{2}}{n(N-1)}\)
\(\delta\)= coeficiente de correlación intraconglomerados. \(V(\overline{\overline{x}})=(1-f)\frac{S^{2}}{n\overline{M}}\left[1+(\overline{M}-1)\delta\right]\)
\(\hat{V}(\overline{\overline{x}})=(1-f)\frac{\hat{S}_{0}^{2}}{n\overline{M}}\left[1+(\overline{M}-1)\hat{\delta}\right]=(1-f)\frac{\hat{S}_{b}^{2}}{n\overline{M}}\)
siendo:\(\hat{S_{0}}^{2}=\frac{N-1}{N\overline{M}-1}\hat{S}_{b}^{2}+\frac{N\left(\overline{M}-1\right)}{N\overline{M}-1}\hat{S}_{w}^{2}\)
\(\hat{V}(\hat{X})=N^{2}\overline{M}^{2}\hat{V}(\overline{\overline{x}})\)
\(\hat{V}(\hat{P})=(1-f)\frac{\hat{S}_{0}^{2}}{n\overline{M}}\left[1+(\overline{M}-1)\hat{\delta}\right]=(1-f)\frac{\hat{S}_{b}^{2}}{n\overline{M}}\)
\(\hat{V}(\hat{A})=N^{2}\overline{M}^{2}\hat{V}(\hat{P})\)
7.1.2. Muestreo con remplazamiento en primera etapa.#
Los estimadors son iguales que en el caso sin remplazamiento
\(V\left(\overline{\overline{X}}\right)=\frac{\sigma_{b}^{2}}{n\overline{M}}\) con \(\sigma_{b}^{2}=\frac{1}{N}\sum_{i=1}^{N}\sum_{J=1}^{\overline{M}}\left(\overline{X}_{i}-\overline{X}\right)^{2}\)
\(V(\overline{\overline{X}})=\frac{\sigma^{2}}{n\overline{M}}\left[1+\left(\overline{M}-1\right)\cdot\delta\right]\) siendo \(\delta\) el coeficiente de correlación intraconglomerados
\(V(\hat{X})=N^{2}\overline{M}^{2}\frac{\sigma_{b}^{2}}{n\overline{M}}\)
\(V(\hat{P})=\frac{\sum_{i=1}^{N}\left(P_{i}-P\right)^{2}}{nN}\ \ \ \text{\ \ V(\ensuremath{\hat{A})=N^{2}\overline{M}^{2}\frac{\sum_{i=1}^{N}\left(P_{i}-P\right)^{2}}{nN}}}\)
7.1.2.1. Estimación de varianzas#
\(\hat{\sigma}'^{2}=\hat{S}_{1,w}^{2}+\frac{\hat{S}_{b}^{2}}{M}\) es un estimador insesgado de \(\sigma^{2}\), \(\hat{S}_{1,w}^{2}=\frac{1}{n\overline{M}}\sum_{i=1}^{n}\sum_{j=1}^{\overline{M}}\left(X_{ij}-\overline{X}_{i}\right)^{2}\)