3. Bases de datos en LangChain.#
En este apartado vamos a ver los siguientes aspectos:
¿Cómo cargar fuentes de datos de todo tipo con Langchain
¿Cómo transformar documentos y fragmentarlos?
¿Cómo convertir documentos en vectores a partir de incrustaciones embeddings
¿Cómo almacenar los datos (internos y externos) en una base de datos vectorizada?
¿Cómo realizar consultas a la base de datos vectorizada y mejorar los resultados con LLMs
Comenzamos con el primer apartado, es decír, cómo poder cargar datos de múltiples fuentes.
3.1. Cargadores de documentos.#
Langchain viene con herramientas de carga integradas para cargar rápidamente archivos en su propio objeto Documento.
Muchos de estos cargadores requieren otras bibliotecas, por ejemplo, la carga de PDF requiere la biblioteca pypdf y la carga de HTML requiere la biblioteca Beautiful Soup . Asegurar de instalar las bibliotecas requeridas antes de usar el cargador (los cargadores informarán si no pueden encontrar las bibliotecas instaladas).
Entre otras librerias es muy conveniente tener instalada la librería Langchain community para loaders en Python .
Para ver la documentación sobre los loaders de LangChain, se puede visitar el siguiente enlace:
https://python.langchain.com/v0.2/docs/integrations/document_loaders/
Procedemos a cargar las librerías e instanciar el modelo de tipo de chat
import langchain
from langchain_openai import ChatOpenAI
from langchain.prompts import PromptTemplate, SystemMessagePromptTemplate,ChatPromptTemplate, HumanMessagePromptTemplate
chat = ChatOpenAI(
model="llama3.2",
base_url = 'http://localhost:11434/v1',
api_key='ollama', # required, but unused,
)
3.2. Cargar documentos de tipo CSV#
from langchain.document_loaders import CSVLoader #pip install langchain-community en una terminal
#Cargamos el fichero CSV
loader = CSVLoader('Fuentes datos/datos_ventas_small.csv',csv_args={'delimiter': ';'})
#Creamos el objeto "data" con los datos desde el cargador "loader"
data = loader.load()
#print(data) #Vemos que se ha creado un documento por cada fila donde el campo page_content contiene los datos
data[0]
print(data[1].page_content)
3.3. Cargar datos HTML#
from langchain.document_loaders import BSHTMLLoader #pip install beautifulsoup4 en una terminal
loader = BSHTMLLoader('Fuentes datos/ejemplo_web.html')
data = loader.load()
data
print(data[0].page_content)
3.4. Cargar datos PDF#
from langchain.document_loaders import PyPDFLoader #pip install pypdf en una terminal
loader = PyPDFLoader('Fuentes datos/Documento tecnologías emergentes.pdf')
pages = loader.load_and_split()
type(pages)
pages[0]
print(pages[0].page_content)
3.5. Caso de uso resumir un documento#
En este apartado vamos a ver un ejemplo concreto sobre como poder utilizar el poder la IA para hacer un resumen de un texto
contenido_pdf=pages[0].page_content
contenido_pdf
human_template = '"Necesito que hagas un resumen del siguiente texto: \n{contenido}"'
human_prompt = HumanMessagePromptTemplate.from_template(human_template)
chat_prompt = ChatPromptTemplate.from_messages([human_prompt])
chat_prompt.format_prompt(contenido=contenido_pdf)
solicitud_completa = chat_prompt.format_prompt(contenido=contenido_pdf).to_messages()
result = chat.invoke(solicitud_completa)
result.content
#Resumir el documento completo
#Creamos una string concatenando el contenido de todas las páginas
documento_completo = ""
for page in pages:
documento_completo += page.page_content # Supongamos que cada página tiene un atributo 'text'
print(documento_completo)
solicitud_completa = chat_prompt.format_prompt(contenido=documento_completo).to_messages()
result = chat.invoke(solicitud_completa)
result.content
3.6. Integración con otras plataformas.#
Existen otros cargadores de documentos que son denominados “integraciones” y pueden ser considerados esencialmente lo mismo que los cargadores normales vistos en la sección anterior, pero con la salvedad y la ventaja de que están integrados con otras plataformas como por ejemplo:
Plataforma de terceros (como Google Cloud, AWS, Google Drive, Dropbox,…)
Base de datos (como MongoDB)
Sitio web específico, como Wikipedia
Permiten cargar vídeos de Youtube (por ejemplo, crear una aplicación de preguntas y respuestas en base a vídeos de Youtube ), conversaciones de WhatsApp y un sinfín de posibilidades.
Con todas estas integraciones, vamos a tener la ventaja de cargar esta información en una base de datos vectorial y después consultar esa información con todas las ventajas que esta información nos puede proporcionar.
La documentación sobre este tipo de cargadores (document loaders - integraciones), se tiene en este enlace:
https://python.langchain.com/v0.2/docs/integrations/document_loaders/
3.6.1. Cargar informaciones de wikipedia.#
A continuación vamos a mostrar un caso de usos que consiste en cargar información de la wikipedia. Como siempre cargamos los paquetes correspondientes y cargamos el chat.
import langchain
from langchain_openai import ChatOpenAI
from langchain.prompts import PromptTemplate, SystemMessagePromptTemplate,ChatPromptTemplate, HumanMessagePromptTemplate
chat = ChatOpenAI(
model="llama3.2",
base_url = 'http://localhost:11434/v1',
api_key='ollama', # required, but unused,
)
#!pip install wikipedia
from langchain.document_loaders import WikipediaLoader # pip install wikipedia en una terminal
Definimos la siguiente función que es la que nos va a servir para obtener y ejecutar lo que necesitamos para hacer consultas apoyadas en la información que figura en la wikipedia.
def responder_wikipedia(persona,pregunta_arg):
# Obtener artículo de wikipedia
docs = WikipediaLoader(query=persona,lang="es",load_max_docs=10) #parámetros posibles en: https://python.langchain.com/v0.2/docs/integrations/document_loaders/wikipedia/
# Observar que el valor de "persona" lo pasamos como parámetro a la función
contexto_extra = docs.load()[0].page_content #para que sea más rápido solo pásamos el primer documento [0] como contexto extra
# Pregunta de usuario, que se la pasamos como parámetro de la función
human_prompt = HumanMessagePromptTemplate.from_template('Responde a esta pregunta\n{pregunta}, aquí tienes contenido extra:\n{contenido}')
# Construir prompt
chat_prompt = ChatPromptTemplate.from_messages([human_prompt])
# Resultado
result = chat.invoke(chat_prompt.format_prompt(pregunta=pregunta_arg,contenido=contexto_extra).to_messages())
print(result.content)
responder_wikipedia("José María Aznar","¿En qué localidad nació?")
3.7. Transformación de documentos.#
Hay que tener en cuenta que después de cargar un objeto Documento desde una fuente, terminará con cadenas de texto desde el campo page_content. Entonces puede haber situaciones en las que la longitud de las cadenas asó obtenidas pueden ser muy grandes para alimentar un modelo (por ejemplo, límite de 8k tokens ~6k palabras). Para resolver este problema, Langchain proporciona transformadores de documentos que permiten dividir fácilmente cadenas del page_content en fragmentos (que se conocen como chunks).
Estos fragmentos servirán más adelante además como componentes útiles en forma de vectores a partir de una incrustación (embeddings ), que luego podremos buscar utilizando una similitud de distancia más adelante. Por ejemplo, si queremos alimentar un LLM con contexto adicional para que sirva como chatbot de preguntas y respuestas, si tenemos varios vectores guardados cada uno con una información diferente, la búsqueda será más rápida puesto que se hará un cálculo del vector guardado que tiene mayor similaridad en lugar de buscar en todos los datos globales.
Veamos ahora un ejemplo ilustrativo de cómo poder hacer todo esto. Para hacer esto vamos a cargar un documento bastante extenso y con mucha información.
with open('Fuentes datos/Historia España.txt', encoding="utf8") as file:
texto_completo = file.read()
# Números de caracteres
len(texto_completo)
Como podemos ver es un documento bastante extenso y lo que vamos a hacer es dividirlo en trozos más pequeños, los cuales tienen la denominación de chunks.
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(separator="\n",chunk_size=1000) #Indicamos que divida cuando se encuentra 1 salto de línea y trate de hacer fragmentos de 1000 caracteres
# Intenta hacer los chunks más o menos del tamaño que se le da, en este caso de 1000
Existen muchas más posibilidades para hacer esto, las cuales se pueden ver en este enlace: https://python.langchain.com/api_reference/text_splitters/character/langchain_text_splitters.character.CharacterTextSplitter.html
Entre estas posibilidaddes está una muy utilizada y es que los cuhunks puedan tener cierto solpamientos, es decir que las últimas palabras del chunk anterior, sean también las palabras del chunk siguiente. Este efecto lo conseguimos con la opción chunk_overlap.
texts = text_splitter.create_documents([texto_completo]) #Creamos documentos gracias al transformador
print(type(texts)) #Verificamos el tipo del objeto obtenido
print('\n')
print(type(texts[0])) #Verificamos el tipo de cada elemento
print('\n')
print(texts[0])
len(texts[0].page_content)
texts[1]
# Veamos la longitud de cada uno de los chunks que se han obtenido
for h in texts:
print(len(h.page_content))
3.8. Incrustación de texto y creación de vectores (embeging)#
NOTA: En este otro apartado, también se puede ver desde diferentes puntos de vista cómo poder trabajar con este tipo embeding.
De cara a trabajar con textos en IA, lo que se suele hacer es transformar esos textos en una representación de los mismos mediante una serie de vectores que contienen información semántica de esos textos. Langchain admite muchas incrustaciones de texto, que pueden convertir directamente texto en una representación vectorizada incrustada.
En resumen, los modelos incrustados crean una representación vectorial de un fragmento de texto . Puedes pensar en un vector como una matriz de números que captura el significado semántico del texto. Al representar el texto de esta manera, puede realizar operaciones matemáticas que le permiten hacer cosas como buscar otras partes del texto que tengan un significado más similar.
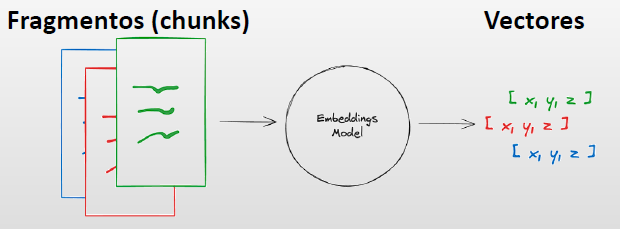
Estos modelos de embeding que utiliza LangChain, se puede ver su explicación en el siguiente enlace:
https://python.langchain.com/v0.2/docs/concepts/#embedding-models
NOTA : Los diferentes modelos de incrustación puede que no interactúen entre sí, lo que significa que necesitaría volver a incrustar un conjunto completo de documentos si cambiara de modelo de incrustación en el futuro. En este se indicará cómo utilizar OpenAI, pues es uno de los métodos más utilizados, pero como se intenta hacer una explicación de estos métodos desde un punto de vista didáctico, sin incurrir en costes, se utilizará ollama para hacer cuestiones prácticas sobre estos métodos.
Se aconseja al lector mirar estos enlaces:
A continuación se muestra un caso práctico sobre cómo utilizar todos estos procesos.
import langchain
from langchain_openai import ChatOpenAI
from langchain.prompts import PromptTemplate, SystemMessagePromptTemplate,ChatPromptTemplate, HumanMessagePromptTemplate
chat = ChatOpenAI(
model="llama3.2",
base_url = 'http://localhost:11434/v1',
api_key='ollama', # required, but unused,
)
Si quisiéramos hacer esto desde OpenAi, el código a utilizar sería el siguiente: (Se ha dejado comentado el código)
NOTA: Para ver cómo empezar con OpenAi, se recomienda ver este apartado
#from langchain_openai import OpenAIEmbeddings
# embeddings = OpenAIEmbeddings(openai_api_key=api_key)
# texto = "Esto es un texto enviado a OpenAI para ser incrustado en un vector n-dimensional"
#embedded_text = embeddings.embed_query(texto)
Sin embargo y con el fin de evitar costes, vamos a ver cómo haríamos estos embeding, utilizando ollama desde LangChain.
from langchain_ollama import OllamaEmbeddings
from langchain_ollama import OllamaEmbeddings
embeddings = OllamaEmbeddings(
model="llama3.2",
)
texto = "Este es el texto que vamos a vectorizar utilizando para ello llama que sale gratuito"
embedded_text = embeddings.embed_query(texto)
type(embedded_text)
embedded_text[:10]
# Este mismo ejercicio pero de forma asíncrona
embedded_text = await embeddings.aembed_query(texto)
Si quisiéramos hacer esto con varios textos deberíamos utilizar una expresión similar a la siguiente:
input_texts = ["Document 1...", "Document 2..."]
vectors = embed.embed_documents(input_texts)
print(len(vectors))
# The first 3 coordinates for the first vector
print(vectors[0][:3])
3.8.1. Incrustación de documentos.#
A continuación se muestra un ejemplo, para ver cómo podemos hacer embedings de documentos, que es la situación real con la que nos encontraremos al trabajar con IA.
Lo primero que hacemos es cargar un documento de tipo CSV
from langchain.document_loaders import CSVLoader
loader = CSVLoader('Fuentes datos/datos_ventas_small.csv',csv_args={'delimiter': ';'})
data = loader.load()
type(data)
type(data[0])
#No podemos incrustar el objeto "data" puesto que es una lista de documentos, lo que espera es una string
# Ejecutar el siguiente comando nos daría un error
#embedded_docs = embeddings.embed_documents(data)
#Creamos una comprensión de listas concatenando el campo "page_content" de todos los documentos existentes en la lista "data"
[elemento.page_content for elemento in data]
embedded_docs = embeddings.embed_documents([elemento.page_content for elemento in data])
#Verificamos cuántos vectores a creado (1 por cada registro del fichero CSV con datos)
len(embedded_docs)
#Vemos un ejemplo del vector creado para el primer registro
embedded_docs[1][:10]
3.9. Almacenamiento de vectores en BD.#
Hasta ahora hemos creado incrustaciones ( embeddings ) en memoria RAM como una lista de Python. Estos embedings en el momento en que nos salgamos de la aplicación se pierden, entonces ¿cómo podemos asegurarnos de que estas incorporaciones persistan en alguna solución de almacenamiento más permanente?
Para conseguir que esta información quede almacenada para futuras consultas, utilizamos un almacén de vectores, también conocido como base de datos de vectores , sus aspectos claves:
Puede almacenar grandes vectores de N dimensiones.
Puede indexar directamente un vector incrustado y asociarlo a su documento string
Se puede “consultar”, lo que permite una búsqueda de similitud de coseno entre un nuevo vector que no está en la base de datos y los vectores almacenados.
Puede agregar, actualizar o eliminar fácilmente nuevos vectores.
Al igual que con los LLM y los modelos de chat, Langchain ofrece muchas opciones diferentes para almacenes de vectores.
Usaremos una base de datos de vectores open source SKLearn , pero gracias a Langchain , la sintaxis es estándar para el resto de BD.
Para hacer este tipo de persistencia LangChain nos ofrece una amplia variedad de Bases de datos, las cuales las podemos consultar utilizando el siguiente link:
https://python.langchain.com/v0.2/docs/integrations/vectorstores/
La metodología que se emplea para este tipo de persistencia de la información, de forma esquemática se puede ver en la siguiente ilustración:

Como ya hemos hecho en casos anteriores, y con la finalidad de mostrar como actuar cuando se quiere hacer este tipo de cosas en IA, a continuación se pasa a ilustrar todo esto con algún ejemplo totalmente práctico.
from langchain_openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.document_loaders import TextLoader
Cargamos el documento y lo dividimos
# Cargar el documento
loader = TextLoader('Fuentes datos/Historia España.txt', encoding="utf8")
documents = loader.load()
# Dividir en chunks
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(chunk_size=500) #Otro método de split basándose en tokens
docs = text_splitter.split_documents(documents)
Procedemos a la creación de embedings
funcion_embedding = OllamaEmbeddings(
model="llama3.2",
)
Para el almacenamiento, utilizamos SKLearn Vector Store
from langchain_community.vectorstores import SKLearnVectorStore #pip install scikit-learn / pip install pandas pyarrow
#!pip install pandas pyarrow
persist_path="./BD/ejemplosk_embedding_db" #ruta donde se guardará la BBDD vectorizada
#Creamos la BBDD de vectores a partir de los documentos y la función embeddings
vector_store = SKLearnVectorStore.from_documents(
documents=docs,
embedding=funcion_embedding,
persist_path=persist_path,
serializer="parquet", #el serializador o formato de la BD lo definimos como parquet
)
# Fuerza a guardar los nuevos embeddings en el disco
vector_store.persist()
Una vez ejecutado el anterior código, y apodemos ver en nuestro disco duro la base de datos creada en la carpeta BD y con denominación ejemplosk_embedding_db.
3.9.1. Búsqueda en la Base de Datos.#
Una vez creada la base de datos podremos ya hacer consultas de similitud de cadenas, para que nos encuentre en la BD los párrafos más similares al litereal que le pasamos. Además nos devuelve párrafos ordenados de mayor a menor similitud.
#Creamos un nuevo documento que será nuestra "consulta" para buscar el de mayor similitud en nuestra Base de Datos de Vectores y devolverlo
consulta = "dame información de la Primera Guerra Mundial"
docs = vector_store.similarity_search(consulta)
print(docs[0].page_content)
El resultado que obtenemos no es lo que realmente estamos buscando, pero hay que tener en cuenta que estamos trabajando en modo local y con resursos muy limitados debido a los escasos recursos que los ordenadores personales tienen para este tipo de trabajos de IA. Muy posiblemente si esto lo hacemos utilizando el api-key de OpenAi el resultado hubiera sido más acertado y además más rápido
3.10. Recuprar datos de una BD.#
Una vez creada la base de datos, y como ya los datos se han persistido y están almacenados en la base de datos, podemos recuperar en cualquier momento la información de esa base de datos y hacer consultas sobre la misma. A continuación se muestra cómo poder hacer esto.
vector_store_connection = SKLearnVectorStore(
embedding=funcion_embedding, persist_path=persist_path, serializer="parquet"
)
print("Una instancia de la BBDD de vectores se ha cargado desde ", persist_path)
vector_store_connection
nueva_consulta = "¿Qué paso en el siglo de Oro?"
docs = vector_store_connection.similarity_search(nueva_consulta)
print(docs[0].page_content)
3.11. Alternativa con ChromaDB.#
La base de datos ChromaDB, también es muy utilizada para realizar este tipo de tareas.
#!pip install langchain_chroma
import chromadb #pip install chromadb en una terminal
from langchain_chroma import Chroma #pip install langchain_chroma en una terminal
# Cargar en ChromaDB
#db = Chroma.from_documents(docs, funcion_embedding,collection_name="langchain",persist_directory='./ejemplo_embedding_db')
#Se crean en el directorio persistente la carpeta con los vectores y otra con las string, aparte de una carpeta "index" que mapea vectores y strings
# Fuerzar a guardar los nuevos embeddings en el disco
#db.persist()
3.12. Añadir nueva información a la BD de vectores#
# Cargar documento y dividirlo
loader = TextLoader('Fuentes datos/Nuevo_documento.txt', encoding="utf8")
documents = loader.load()
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(chunk_size=500)
docs = text_splitter.split_documents(documents)
# Cargar en Chroma
#db = Chroma.from_documents(docs, embedding_function,persist_directory='./ejemplo_embedding_db')
# docs = db.similarity_search('insertar_nueva_búsqueda')
3.13. Comprensión y optimización de resultados a partir de LLMs.#
En el apartado anterior hemos visto cómo poder encontrar párrafos de un texto que se asimilan mucho a la consulta que estamos planteando. Pero el resultado que obtenemos no presenta el formato más adecuado para la respuesta que buscamos. En este apartado vamos a ver cómo podemos conseguir esto.
No estamos realizando compresión en el sentido tradicional, sino que utilizamos un LLM para tomar una salida de texto de un documento de mayor tamaño y la limpia / optimiza en una salida más corta y relevante.
from langchain.document_loaders import WikipediaLoader
from langchain_openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.document_loaders import TextLoader
from langchain_community.vectorstores import SKLearnVectorStore
#cargamos documentos desde la wikipedia
loader = WikipediaLoader(query='Lenguaje Python',lang="es")
documents = loader.load()
Obtenemos de esta manera un documento lo suficientemente grande como para poder trabajar con el para demostrar esta facilidad de LangChain
len(documents)
Procedemos a dividir el documento
# División en fragmentos
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(chunk_size=500)
docs = text_splitter.split_documents(documents)
len(docs)
funcion_embedding = OllamaEmbeddings(
model="llama3.2",
)
persist_path="./BD/ejemplo_wiki_bd" #ruta donde se guardará la BBDD vectorizada
#Creamos la BBDD de vectores a partir de los documentos y la función embeddings
vector_store = SKLearnVectorStore.from_documents(
documents=docs,
embedding=funcion_embedding,
persist_path=persist_path,
serializer="parquet", #el serializador o formato de la BD lo definimos como parquet
)
# Fuerza a guardar los nuevos embeddings en el disco
vector_store.persist()
Hacemos una consulta normal de similitud coseno
#Creamos un nuevo documento que será nuestra "consulta" para buscar el de mayor similitud en nuestra Base de Datos de Vectores y devolverlo
consulta = "¿Por qué el lenguaje Python se llama así?"
docs = vector_store.similarity_search(consulta)
print(docs[0].page_content)
Como podemos ver la respuesta obtenida ( como antes quizá sin mucho sentido para la pregunta formulada) presenta un aspecto que no es el más adecuado para la presentación a la persona que formula la pregunta. Por ello, a continuación vamos a ver cómo podemos reconducir esto para obtener un resultado que se adapte más a nuestras pretensiones.
3.13.1. Consulta con compresión contextual usando LLMs.#
Para obtener el resultado pretendido, vamos a importar las siguientes librerías
from langchain_openai import ChatOpenAI
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import LLMChainExtractor
llm = ChatOpenAI(
model="llama3.2", #el parámetro temperatura define la aleatoriedad de las respuestas, temperatura = 0 significa el mínimo de aleatoriedad
temperature=0,
api_key='ollama', # required, but unused,
)
compressor = LLMChainExtractor.from_llm(llm)
compression_retriever = ContextualCompressionRetriever(base_compressor=compressor, base_retriever=vector_store.as_retriever())
compressed_docs = compression_retriever.invoke("¿Por qué el lenguaje Python se llama así?")
compressed_docs[0].page_content