10. La Api de OpenAI.#
Los assistants de OpenAI representan una revolución en la integración de inteligencia artificial personalizada y conversacional en aplicaciones y servicios. Son agentes que utilizan modelos de lenguaje avanzados, como GPT-4 Turbo, para automatizar tareas, interactuar con usuarios en lenguaje natural y ejecutar funciones adaptadas según las necesidades específicas del contexto.
10.1. ¿Qué son los OpenAI Assistants?#
Un OpenAI Assistant es un agente digital configurable que utiliza modelos de lenguaje entrenados con grandes cantidades de datos para responder preguntas, ejecutar funciones, analizar información y brindar asistencia en una amplia variedad de tareas. Estos asistentes se configuran a través de instrucciones (que definen personalidad y comportamiento), conjuntos de datos personalizados, y funciones programadas por el desarrollador.
Los asistentes son inteligencias artificiales generativas diseñadas para propósitos específicos, utilizando los modelos de OpenAI (como GPT-4 y GPT-3.5, etc.). Estos asistentes tienen acceso a archivos, pueden mantener el contexto de la conversación (historial) y pueden usar herramientas especializadas.
10.2. Características principales#
Personalización: Es posible definir el comportamiento y personalidad del asistente mediante instrucciones precisas, así como entrenarlo con datos propios (PDFs, artículos, bases de datos, etc.).
Función de llamada: Los assistants pueden integrarse con funciones externas y APIs para acceder a información en tiempo real, automatizar cálculos o interactuar con otros servicios digitales.
Gestión de datos: Capaces de procesar tanto datos estructurados (JSON, hojas de cálculo) como no estructurados (texto libre, documentos), extrayendo y transformando información relevante.
Escalabilidad: La infraestructura de OpenAI permite atender miles de usuarios en simultáneo sin perder calidad en las respuestas.
Aprendizaje continuo: Gracias a su naturaleza de entrenamiento, los assistants pueden mejorar su precisión y relevancia conforme reciben nuevos datos o retroalimentación.
10.3. Ventajas de utilizar OpenAI Assistants#
Automatización y productividad: Permiten gestionar tareas repetitivas, asistir en proyectos, analizar grandes volúmenes de datos y mejorar la atención al cliente.
Accesibilidad y apertura: El enfoque suele ser abierto para desarrolladores, lo que facilita la colaboración, la creación de asistentes especializados y la rápida evolución tecnológica.
Integración sencilla: Herramientas y APIs modernas permiten que los asistentes se integren fácilmente en aplicaciones web, equipos de trabajo y sistemas empresariales.
Es de advertir que tal y como figura en su página oficial, en el momento de redactar este documento, esta api está deprecated y dejará de estar disponible el 26 de agosto de 2026, siendo sustituida por la api de responses.
A pesar de todo esto se ha creído conveniente proceder a presentar esta las dos API’s, con la finalidad de que el lector sepa de donde estamos y cuales serán los nuevos cambios hacia la nueva API.
En la siguiente imagen mostramos una visualización que detalla cómo esta compuesta esta API.
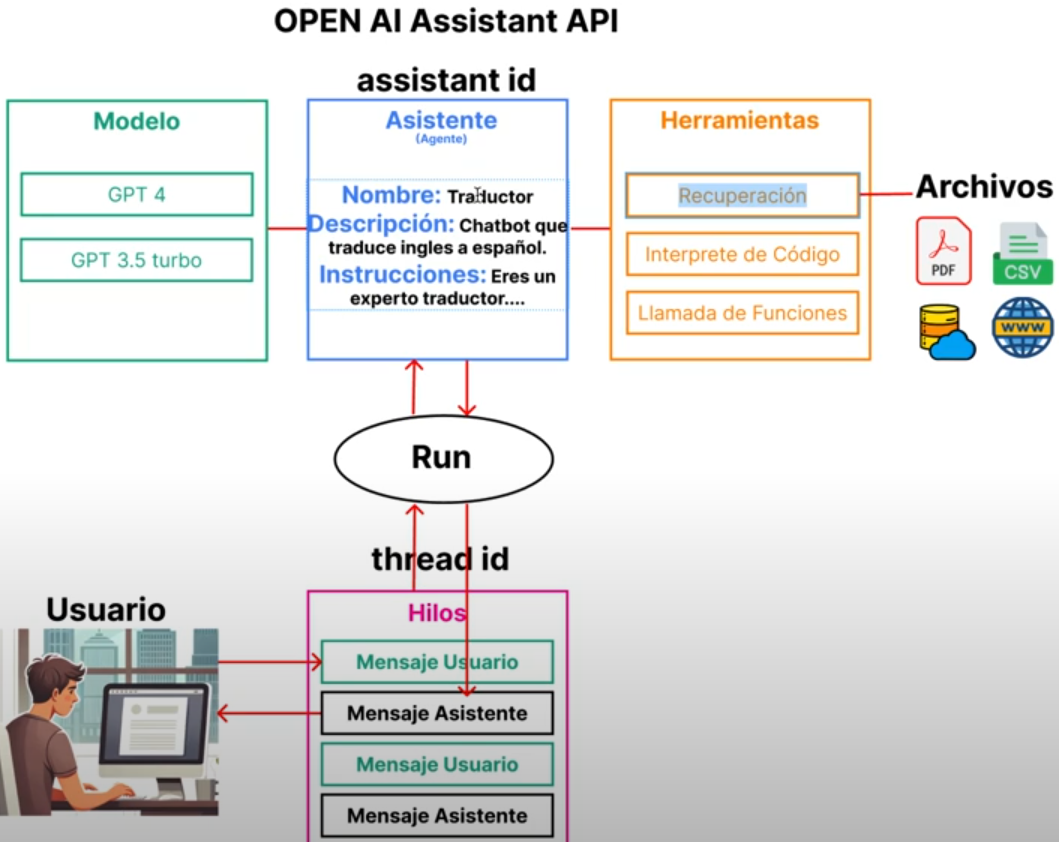
En esa figura, observamos los siguientes componentes que pueden configurar el assitants de OpenAi:
Los modelos LLM, que puede ser cualquiera de los modelos que tiene OpenAi, en esta caso se hace referencia a los modelos GPT 4 ó GPT 3.5 turbo.
Un asistente va a tener un identificador (Id) que es único para cada asistente, un nombre, una descripción e instrucciones.
Herramientas o Tools. Las mas importantes son las de recuperación (retrieval), interprete de Código (para trabajar código python) y la llamada a funciones.
Los Thread o hilos de conversaciones. Cada hilo viene a ser una sesion conversación con un usuario. En cada hilo se guarda los promts del usuario y las respuestas correspondientes del asistente
Los Run son los engranajes entre los asistentes y los thread.
A continuación vamos a mostrar un ejemplo de cómo podemos crear un asistente con la herramienta de retrieval.
#!pip install --upgrade openai
# de esta forma obtenemos los resultados de forma más estética
from pprint import pprint
# importamos JSON para poder trabajar con este tipo de datos
import json
# importamos el paqute de openai
from openai import OpenAI
import time
10.4. Ficheros de configuración de claves API#
A continuación, lo que hacemos es recuperar la clave API de OpenAI, pero para no mostrarla aquí utilizaremos una técnica muy extendida entre los desarrolladores de Python, que consiste en generar un fichero denominado .env y que haciendo una pequeña digresión del tema central de este documento consiste en lo siguiente: Un archivo .env en Python es un archivo de texto plano que almacena variables de entorno, como contraseñas o claves API, para mantener la información sensible fuera del código fuente y del repositorio de control de versiones. Se utiliza con la biblioteca python-dotenv, la cual carga estos pares clave-valor en el entorno de ejecución de la aplicación. Para usarlo, se instala la biblioteca, se crea un archivo .env con las variables, y luego se utiliza os.getenv() para acceder a ellas en el código de Python.
10.4.1. ¿Para qué se usan los archivos .env?#
Seguridad: Permiten mantener información confidencial, como credenciales de bases de datos o claves de API, separada del código fuente, evitando que se exponga accidentalmente.
Configuración: Facilitan la gestión de diferentes configuraciones para distintos entornos (desarrollo, pruebas, producción) sin tener que modificar el código.
Buenas prácticas: Es una práctica recomendada para separar los datos de configuración del código, lo que hace el proyecto más limpio y seguro.
10.4.2. ¿Cómo se usan en Python?.#
Primero instalamos la biblioteca:
pip install python-dotenv
Se crea un archivo denominado .env enla raíz del proyecto y se añaden las variables de entorno en formato CLAVE = VALOR, por ejemplo:
Note
API_KEY=tu_clave_secreta
DATABASE_URL=postgresql://usuario:contraseña@host:puerto/db
Y ahora ya podemos cargar y usar las variables de entorno en el código de la siguiente manera:
import os
from dotenv import load_dotenv
# Carga las variables del archivo .env en el entorno
load_dotenv()
# Accede a las variables con os.getenv()
api_key = os.getenv("API_KEY")
db_url = os.getenv("DATABASE_URL")
print(f"La API Key es: {api_key}")
print(f"La URL de la base de datos es: {db_url}")
import os
from dotenv import load_dotenv
load_dotenv()
openai_key = os.getenv("openai_key")
# Si queremos ver la api key
#print(openai_key)
# Creamos el cliente de OpenAI
client = OpenAI(
api_key = openai_key
)
# paso 2: Cargar archivos que nuestro asistente necesita para el tipo retrieval
# pueden ser de tipo .pdf, excel, worf, etc
#El tamaño máximo del archivo debe ser 512 MB
# máximo almacenamiento 100 GB
# Cargamos un pequeño fichero .pdf que se encuenta en : https://www.semfyc.es/storage/wp-content/uploads/2021/12/02_Unidad_2020-8.pdf
# El contenido del fichero es el dolor de oídos en personas adultas
file = client.files.create(
file = open("oidos.pdf","rb"),
purpose = 'assistants'
)
# imprimimos el identificador del fichero
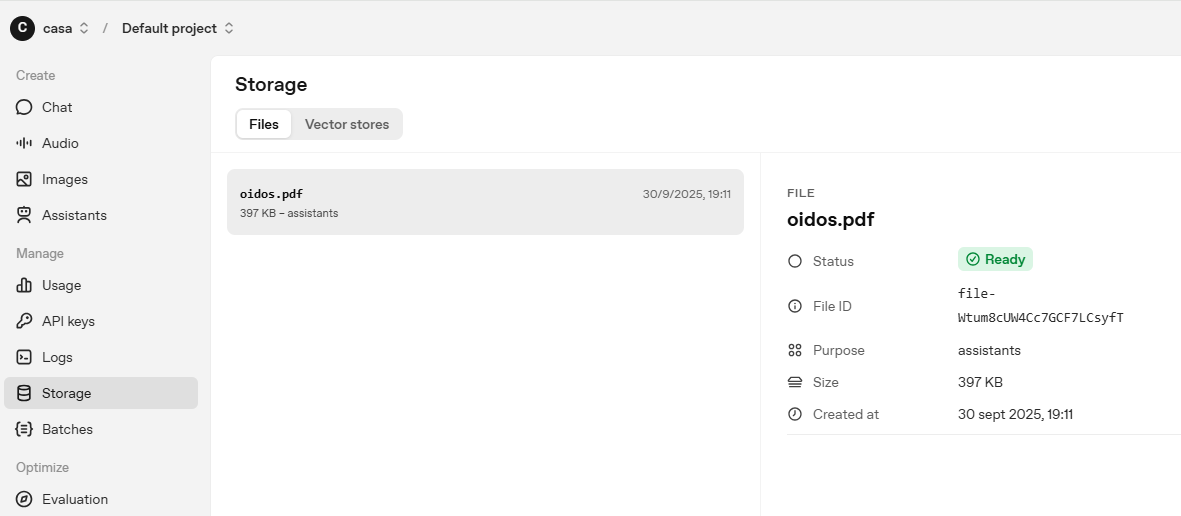
print(f"El identificador del fichero es:{file.id}")
Este identificador también lo podemos ver en el playground de OpenAI (https://platform.openai.com/chat/edit?models=gpt-5) en el menú denominado: Storage.
file
# creamos un asistente sin vector_stores
assistant = client.beta.assistants.create(
name="Mi Assistant",
instructions="Eres un otorrino de mucho prestigio y con grandes conocimientos sobre el funcionamiento del oído",
model="gpt-4-turbo",
tools=[{"type": "file_search"}]
)
# 3. Crear thread con archivo adjunto
thread = client.beta.threads.create(
messages=[
{
"role": "user",
"content": "¿Cuáles son los puntos principales de este documento?",
"attachments": [
{
"file_id": file.id,
"tools": [{"type": "file_search"}]
}
]
}
]
)
# 4. Ejecutar
run = client.beta.threads.runs.create(
thread_id=thread.id,
assistant_id=assistant.id
)
run
print(f"Run creado: {run.id}")
print(f"Estado inicial: {run.status}")
# 1. ESPERAR A QUE TERMINE LA EJECUCIÓN
while run.status in ['queued', 'in_progress', 'cancelling']:
time.sleep(1) # Esperar 1 segundo
run = client.beta.threads.runs.retrieve(
thread_id=thread.id,
run_id=run.id
)
print(f"Estado actual: {run.status}")
# 1. ESPERAR A QUE TERMINE LA EJECUCIÓN
while run.status in ['queued', 'in_progress', 'cancelling']:
time.sleep(1) # Esperar 1 segundo
run = client.beta.threads.runs.retrieve(
thread_id=thread.id,
run_id=run.id
)
print(f"Estado actual: {run.status}")
# 2. VERIFICAR SI COMPLETÓ EXITOSAMENTE
if run.status == 'completed':
print("✅ Ejecución completada")
# 3. OBTENER TODOS LOS MENSAJES DEL THREAD
messages = client.beta.threads.messages.list(
thread_id=thread.id,
order="asc" # Del más antiguo al más reciente
)
# 4. EXTRAER LA RESPUESTA DEL ASSISTANT
print("\n" + "="*50)
print("RESPUESTA DEL ASSISTANT:")
print("="*50)
# El último mensaje será la respuesta del assistant
last_message = messages.data[-1] # Último mensaje
if last_message.role == 'assistant':
# Extraer el texto de la respuesta
respuesta_texto = last_message.content[0].text.value
print(respuesta_texto)
# 5. OBTENER CITAS Y ANOTACIONES (si las hay)
annotations = last_message.content[0].text.annotations
if annotations:
print("\n" + "="*30)
print("CITAS Y REFERENCIAS:")
print("="*30)
for i, annotation in enumerate(annotations):
if hasattr(annotation, 'file_citation'):
citation = annotation.file_citation
print(f"Cita {i+1}: {citation.quote}")
print(f"Archivo ID: {citation.file_id}")
elif hasattr(annotation, 'file_path'):
file_path = annotation.file_path
print(f"Archivo referenciado {i+1}: {file_path.file_id}")
elif run.status == 'failed':
print(f"❌ Error en la ejecución: {run.last_error}")
elif run.status == 'requires_action':
print("⚠️ Requiere acción adicional")
print(f"Acción requerida: {run.required_action}")
else:
print(f"Estado inesperado: {run.status}")
# Ahora borramos el fichero que hemos almacenado anteriormente, al fin de no incurrir en costos por el almacenamiento
client.files.delete(file.id)
10.5. Llamadas a funciones.#
Ya hemos visto antes que otra de las herramientas que se pueden utilizar con los assistents, son las llamadas a funciones, cuya documentación la podemos encontrar en el siguiente enlace:
https://platform.openai.com/docs/guides/function-calling
# cramos nestra primera función
# NOMBRE-DESCRPCIÓN-PARÁMETROS
sendEmail = {
"name" : "sendEmail",
"description":"The function allows us to send email by specifying an email address and the title and descrption of the email.",
"parameters":{
"type": "object",
"properties":{
"email": {
"type":"string",
"description":"Email address of the receiver"
},
"subject":{
"type":"string",
"description": "Subject of the email"
},
"textBody":{
"type":"string",
"description":"Body of the email"
}
},
"required":["email","subject","textBody"]
}
}
# creamos la segunda función
getCurrentWeather ={
"name":"getCurrentWeather",
"description": "Get the weather in location",
"parameters" :{
"type": "object",
"properties":{
"location": {"type":"string","description":"The city and e.g. San Francisco , CA"},
"unit":{"type":"string","enum":["c","f"]}
},
"required": ["location"]
}
}
# creamos el asistente
assistant = client.beta.assistants.create(
name="Chatbot que responde a las preguntas del cliente",
instructions="Eres un chatbot de la Peluqueria LLM Master y te has especializado en enviar emails. Usa tu concimiento para responder a las preguntas del usuario",
model = "gpt-3.5-turbo-1106",
tools = [
({'type':'function','function': sendEmail}),
({'type':'function','function': getCurrentWeather})
]
)
print(assistant.id)
# creamos el hilo
thread = client.beta.threads.create()
print(thread.id)
# creamos el primer mensaje del usuario y lo pasamos al hilo
message = client.beta.threads.messages.create(
thread_id = thread.id,
role = "user",
content ="que tiempo hace en Madrid?"
)
# ejecutamos el asistente para obtener la respuesta
run= client.beta.threads.runs.create(
thread_id = thread.id,
assistant_id = assistant.id
)
print(run.id)
# Recupera el estado de ejecución (aqui vemos que require_action)
# Esto le está diciendo al modelo, que necesita información de nuestra función
# es decir, que necesitamos llamar a una función que permita enviar el email
run = client.beta.threads.runs.retrieve(
thread_id = thread.id,
run_id=run.id
)
print(run.status)
# como obtenemos requires_action entonces tenemos que llamar a una función
# ejemplo una llamada a una api para enciar un mail, titulo y descripción
# Ejemplo: Una llamada a un api para obtener la temperatura de Madrid
## tools_to_call= a qué función tenemos que llamar
tools_to_call = run.required_action.submit_tool_outputs.tool_calls
print(len(tools_to_call)) # cuantas llamadas tengoq ue hacer, imaginate que es más de una
print(tools_to_call)
10.6. Interprete de código.#
Recordar que esta es otra de las herramientas de los asistentes, según hemos visto al comienzo de este tema. Esta herramienta permite escribir y ejecutar código en python en un entorno seguro y aislado. Este entorno es capaz de procesar archivos de diversos formatos, generar resultados en tiempo real y crear imágenes de gráficos. Veamos a continuación cómo funciona este interprete de código.
# suponemos que ya hemos creado el ciente
assistant = client.beta.assistants.create(
name = "profesor matemáticas",
instructions = "Eres un chatbot especializado en resolver problemas matemáticos. Escribe y ejecuta código para responder las preguntas de matemáticas",
model = "gpt-3.5-turbo-1106",
tools =[({'type':'code_interpreter'})]
)
print(assistant.id)
#creamos el hilo
thread = client.beta.threads.create()
print(thread.id)
# creamos el primer mensaje del usuario y lo pasamos al hilo
message = client.beta.threads.messages.create(
thread_id=thread.id,
role = "user",
content="tengo el siguiente problema matemático '5x+5=10'. ¿cual es el valor de x?"
)
# ejecutamos el asistente para obtener la respuesta
run = client.beta.threads.runs.create(
thread_id=thread.id,
assistant_id=assistant.id
)
print(run.id)
# leemos los mensaje
messages = client.beta.threads.messages.list(
thread_id=thread.id
)
with open("messages.json","w") as f:
messages_json = messages.model_dump()
json.dump(messages_json,f,indent=4)
print("Ver conversación:")
for message in messages.data:
pprint(message.role+": "+message.content[0].text.value)
11. Responses.#
Como ya se ha dicho anteriormente, la API de asistentes quedará obsoleta a partir del 26 de agosto de 2026, y será sustituida por la API de Responses. Para ayuda de la migración, OpenAi ha creado la página siguiente:
https://platform.openai.com/docs/assistants/migration
La equivalencia entre una API y la otra se puede ver en el siguiente cuadro:

En lo que sigue vamos a hacer una introducción a esta nueva API denominada Responses. Para seguir con este código, vamos a suponer que ya tenemos creado el objeto client como se ha hecho al comienzo de este documento. Comenzamos con un ejemplo bien sencillo para hacer una introducción a este elemento.
from openai import OpenAI
response = client.responses.create(
model ="gpt-4o-mini",
input="Dime algo sobre la historia de Valladolid"
)
Lo que se devuelve es un objeto de tipo JSON, cuyo contenido se ve a continuación.
pprint(response)
Para obtener el contenido e la respuesta devuelta, lo podemos hace dela siguiente manera:
response.output[0].content[0].text
11.1. Persistencia entre conversaciones.#
La API de Responses de OpenAI puede utilizarse con objetos conversation para mantener el estado de conversación de manera persistente. Aquí te proporciono un ejemplo completo de cómo utilizarla:
from openai import OpenAI
# 1. Crear un objeto conversation
conversation = client.conversations.create()
# 2. Primera respuesta usando el conversation
response = client.responses.create(
model="gpt-4o-mini",
input=[{"role": "user", "content": "¿Cuáles son los 5 Ds del dodgeball?"}],
conversation=conversation.id
)
print(f"Primera respuesta: {response.output_text}")
# 3. Segunda respuesta usando la misma conversation
# El contexto se mantiene automáticamente
second_response = client.responses.create(
model="gpt-4o-mini",
input=[{"role": "user", "content": "¿Puedes explicar el último D?"}],
conversation=conversation.id
)
print(f"Segunda respuesta: {second_response.output_text}")
Note
La API de Responses la podemos encontrar en el siguiente enlace:
https://platform.openai.com/docs/api-reference/responses/create
La API de conversation la podemos encontrar en la siguiente dirección:
https://platform.openai.com/docs/api-reference/conversations/create
El mantenimiento del estado de una conversación lo podemos encontrar en el siguiente enlace
https://platform.openai.com/docs/guides/conversation-state?api-mode=responses
Un ejemplo similar, pero con gestión manual del historial es el siguiente:
from openai import OpenAI
#client = OpenAI()
# Mantener historial manualmente
history = [
{"role": "user", "content": "cuéntame un chiste"}
]
response = client.responses.create(
model="gpt-4o-mini",
input=history,
store=False
)
print(f"Chiste: {response.output_text}")
# Agregar la respuesta al historial
history += [{"role": el.role, "content": el.content} for el in response.output]
history.append({"role": "user", "content": "explica por qué es gracioso"})
second_response = client.responses.create(
model="gpt-4o-mini",
input=history,
store=False
)
print(f"Explicación: {second_response.output_text}")
Se puede conseguir un efecto similar utilizando el parámetro previous_response_id. Veamos un ejemplo:
from openai import OpenAI
#client = OpenAI()
# Primera respuesta
response = client.responses.create(
model="gpt-4o-mini",
input="cuéntame un chiste",
store=True
)
print(f"Chiste: {response.output_text}")
# Segunda respuesta enlazada
second_response = client.responses.create(
model="gpt-4o-mini",
previous_response_id=response.id,
input=[{"role": "user", "content": "explica por qué es gracioso"}],
store=True
)
print(f"Explicación: {second_response.output_text}")
Ventajas del objeto conversation:
El objeto conversation ofrece varias ventajas :
Persistencia: Mantiene el estado a través de sesiones, dispositivos o trabajos
Identificador durable: Cada conversación tiene un ID único persistente
Gestión automática: No necesitas manejar manualmente el historial de mensajes
Sin límite de 30 días: A diferencia de las respuestas individuales, las conversaciones no tienen TTL
Consideraciones importantes:
Las respuestas individuales se guardan por 30 días por defecto
Todos los tokens de entrada previos en la cadena se facturan como tokens de entrada
Las conversaciones almacenan items que pueden ser mensajes, llamadas a herramientas y otros datos
OpenAI no utiliza datos enviados vía API para entrenar modelos sin consentimiento explícito
El método más recomendado es usar el objeto conversation ya que simplifica significativamente la gestión del estado y proporciona persistencia a largo plazo.
11.2. La API de Files.#
Existe también esta API para poder almacenar ficheros con los que se va a trabajar en OpenAi (tenr en cuenta que mantener estos ficheros tiene un coste). La documentación de esta API se puede encontrar en el siguiente enlace:
https://platform.openai.com/docs/api-reference/files/create
Existen diferentes posibilidades qur ofrece esta API, como subir ficheros, recuperarlos, borrarlos,etc. Vamos a generar ahora un ejemplo de como subir un fichero:
from openai import OpenAI
client = OpenAI()
file = client.files.create(
file=open("oidos.pdf", "rb"),
purpose="assistants",
expires_after={
"anchor": "created_at",
"seconds": 4000
}
)
# Veamos los ficheros existente:
client.files.list()
Como ya hemos indicado en un apartado anterior, podemos ver el fichero en el dashboard de OpenAi y alli borrarrlo, pero otra forma de hacer esto es la siguiente:
client.files.delete(file.id)
11.3. Vector store.#
Un “vector store” en OpenAI es un almacén de información diseñado para búsqueda semántica y recuperación aumentada por recuperación (RAG), donde los documentos se dividen en fragmentos, se convierten en incrustaciones vectoriales y se indexan para consultas por similitud, de modo que un asistente pueda responder con precisión citando y recuperando los trozos más relevantes de los archivos adjuntos.
En la práctica, un objeto vector store actúa como contenedor de archivos procesados para búsqueda: al añadir un archivo, se parsea, se trocea en chunks, se generan embeddings y se guarda en un índice que soporta coincidencias por palabras clave y por semántica, lo que permite recuperar pasajes relevantes dado un prompt o pregunta.
Estos almacenes pueden vincularse a asistentes o a conversaciones, habilitando la herramienta de búsqueda de archivos para que el modelo consulte directamente los propios datos; al adjuntarlo, las respuestas del agente pueden fundamentarse en los documentos, mejorando precisión y trazabilidad.
Flujo típico:
Ingesta: crear el vector store y subir uno o varios archivos; la plataforma gestiona el análisis, chunking y embeddings de forma asíncrona, con estado visible en contadores de ingesta.
Consulta: la pregunta del usuario se convierte en vector y se ejecuta una búsqueda por similitud (p. ej., distancia coseno) sobre los chunks, devolviendo los más relevantes para que el modelo los use como contexto.
Gestión: se pueden añadir o eliminar archivos individualmente o por lotes (hasta 500 por batch), y hay límites como tamaño máximo por archivo (512 MB) y tope de tokens por archivo.
Casos de uso comunes:
Búsqueda semántica y FAQ sobre documentación técnica o bases de conocimiento internas.
Asistentes de soporte que responden con fragmentos de manuales o políticas adjuntas al vector store.
Recomendación, clustering y clasificación basados en proximidad semántica de embeddings.
Detalles operativos relevantes:
Adjuntar un vector store otorga capacidad de “file search” al asistente o al hilo, normalmente con un único vector store por asistente/hilo para control de ámbito.
La ingesta es asíncrona; los SDK proporcionan utilidades “create and poll” para esperar a que finalice antes de consultar.
Existen endpoints y objetos específicos para archivos y lotes de archivos dentro del vector store, con propiedades para auditar el estado y conteos de items procesados.
En resumen, los objetos vector store son la pieza nativa de OpenAI para convertir archivos en contexto consultable mediante embeddings y similitud, permitiendo construir agentes y flujos RAG sin desplegar una base vectorial externa.
El API de estos elementos se puede encontrar en este enlace:
https://platform.openai.com/docs/api-reference/vector-stores/create
continuación se muestran algunos ejemplos de cómo poder utilizar estos elementos:
11.3.1. Creación de Vector Store#
from openai import OpenAI
client = OpenAI()
# Crear un nuevo vector store
vector_store = client.beta.vector_stores.create(
name="Mi Base de Conocimientos",
expires_after={
"anchor": "last_active_at",
"days": 7
}
)
print(f"Vector Store creado con ID: {vector_store.id}")
11.3.2. Subida de archivos.#
# Subir archivos uno por uno
file = client.files.create(
file=open("documento.pdf", "rb"),
purpose="assistants"
)
# Añadir archivo al vector store
vector_store_file = client.beta.vector_stores.files.create(
vector_store_id=vector_store.id,
file_id=file.id
)
# Subida masiva (más eficiente para múltiples archivos)
file_paths = ["doc1.pdf", "doc2.txt", "doc3.docx"]
file_streams = [open(path, "rb") for path in file_paths]
file_batch = client.beta.vector_stores.file_batches.upload_and_poll(
vector_store_id=vector_store.id,
files=file_streams
)
print(f"Batch procesado: {file_batch.status}")
11.3.3. Gestión de estados.#
# Monitorear el progreso de procesamiento
import time
def wait_for_processing(vector_store_id):
while True:
vs = client.beta.vector_stores.retrieve(vector_store_id)
print(f"Estado: {vs.status}")
print(f"Archivos procesados: {vs.file_counts.completed}/{vs.file_counts.total}")
if vs.status == "completed":
break
elif vs.status == "failed":
raise Exception("Error en el procesamiento")
time.sleep(2)
wait_for_processing(vector_store.id)
11.3.4. Vinculación con asistentes#
# Crear asistente con vector store
assistant = client.beta.assistants.create(
name="Asistente Documentos",
instructions="Responde basándote en los documentos adjuntos",
model="gpt-4-turbo",
tools=[{"type": "file_search"}],
tool_resources={
"file_search": {
"vector_store_ids": [vector_store.id]
}
}
)
# O actualizar asistente existente
client.beta.assistants.update(
assistant_id=assistant.id,
tool_resources={
"file_search": {
"vector_store_ids": [vector_store.id]
}
}
)
11.3.5. Consultas y búsquedas.#
# Crear hilo de conversación
thread = client.beta.threads.create()
# Hacer pregunta que active la búsqueda
message = client.beta.threads.messages.create(
thread_id=thread.id,
role="user",
content="¿Cuáles son las políticas de vacaciones según la documentación?"
)
# Ejecutar asistente
run = client.beta.threads.runs.create_and_poll(
thread_id=thread.id,
assistant_id=assistant.id
)
# Obtener respuesta
messages = client.beta.threads.messages.list(thread_id=thread.id)
print(messages.data[0].content[0].text.value)
11.3.6. Administración de archivos.#
# Listar archivos en el vector store
files = client.beta.vector_stores.files.list(
vector_store_id=vector_store.id
)
for file in files.data:
print(f"Archivo: {file.id}, Estado: {file.status}")
# Eliminar archivo específico
client.beta.vector_stores.files.delete(
vector_store_id=vector_store.id,
file_id=file.id
)
# Obtener información detallada
file_info = client.beta.vector_stores.files.retrieve(
vector_store_id=vector_store.id,
file_id=file.id
)
11.3.7. Gestión completa del ciclo de vida.#
class VectorStoreManager:
def __init__(self, client):
self.client = client
def create_knowledge_base(self, name, documents):
# Crear vector store
vs = self.client.beta.vector_stores.create(name=name)
# Subir documentos en lote
file_streams = [open(doc, "rb") for doc in documents]
batch = self.client.beta.vector_stores.file_batches.upload_and_poll(
vector_store_id=vs.id,
files=file_streams
)
# Cerrar streams
for stream in file_streams:
stream.close()
return vs.id if batch.status == "completed" else None
def cleanup_expired(self):
# Listar todos los vector stores
stores = self.client.beta.vector_stores.list()
for store in stores.data:
if store.status == "expired":
self.client.beta.vector_stores.delete(store.id)
print(f"Eliminado vector store expirado: {store.id}")
# Uso
manager = VectorStoreManager(client)
vs_id = manager.create_knowledge_base(
"Políticas Empresa",
["politicas.pdf", "manual.docx", "procedimientos.txt"]
)
11.3.8. Manejo de errores#
try:
# Operación con vector store
result = client.beta.vector_stores.files.create(
vector_store_id="vs_invalid",
file_id="file_invalid"
)
except Exception as e:
if "not found" in str(e).lower():
print("Vector store o archivo no encontrado")
elif "limit" in str(e).lower():
print("Límite de archivos alcanzado")
else:
print(f"Error inesperado: {e}")
11.4. Caso de uso con Responses.#
En este apartado vamos a replicar el apartado anterior de leer un fichero y sacar información del mismo pero en este caso utilizando la API de Responses en lugar de assistant.
file = client.files.create(
file = open("oidos.pdf","rb"),
purpose = 'assistants'
)
# imprimimos el identificador del fichero
print(f"El identificador del fichero es:{file.id}")
response = client.responses.create(
model="gpt-4o-mini",
input=[
{
"role": "user",
"content": [
{
"type": "input_text",
"text": "¿Cuáles son los puntos principales de este documento?"
},
{
"type": "input_file",
"file_id": file.id # Aquí usas el file.id directamente
}
]
}
]
)
print(response)
# Borramos el objero response
response2 = client.responses.delete(response.id)
print(response2)
Ahora realizamos el mismo procedimiento pero utilizando un vector store
# 2. Crear vector store
vector_store = client.vector_stores.create(
name="Documentos para análisis"
)
# 3. Agregar archivo al vector store
client.vector_stores.files.create(
vector_store_id=vector_store.id,
file_id=file.id
)
# 4. Usar el Responses API con el vector store
response = client.responses.create(
model="gpt-4o-mini",
tools=[{
"type": "file_search",
"vector_store_ids": [vector_store.id],
"max_num_results": 20
}],
input="¿Cuáles son los puntos principales de este documento?",
)
print(response)
response.output[1].content[0].text
# borramos elobjeto response
# Borramos el objero response
response = client.responses.delete(response.id)
print(response)
# Veamos cuantos vector Store tenemos
vector_stores = client.vector_stores.list()
print(vector_stores)
Un codigo mas completo seria el siguiente:
from datetime import datetime
def listar_vector_stores():
try:
# Obtener la lista de vector stores
vector_stores = client.vector_stores.list()
if not vector_stores.data:
print("No tienes vector stores creados.")
return
print(f"Encontrados {len(vector_stores.data)} vector stores:")
print("=" * 80)
for i, vs in enumerate(vector_stores.data, 1):
# Convertir timestamp a fecha legible
created_date = datetime.fromtimestamp(vs.created_at).strftime("%Y-%m-%d %H:%M:%S")
print(f"{i}. Vector Store:")
print(f" ID: {vs.id}")
print(f" Nombre: {vs.name or 'Sin nombre'}")
print(f" Creado: {created_date}")
print(f" Estado: {vs.status}")
print(f" Archivos:")
print(f" - Total: {vs.file_counts.total}")
print(f" - En progreso: {vs.file_counts.in_progress}")
print(f" - Completados: {vs.file_counts.completed}")
print(f" - Fallidos: {vs.file_counts.failed}")
print(f" - Cancelados: {vs.file_counts.cancelled}")
print(f" Tamaño: {vs.usage_bytes} bytes ({vs.usage_bytes / (1024*1024):.2f} MB)")
# Si hay metadatos, mostrarlos
if hasattr(vs, 'metadata') and vs.metadata:
print(f" Metadatos: {vs.metadata}")
print("-" * 80)
except Exception as e:
print(f"Error al obtener vector stores: {e}")
# Ejecutar la función
listar_vector_stores()
# Borramos los cuatro vector store
from datetime import datetime, timedelta
import time
def eliminar_todos_los_vector_stores():
"""
Elimina todos los vector stores de tu cuenta OpenAI
PRECAUCIÓN: Esta operación es irreversible
"""
try:
# Obtener lista de todos los vector stores
print("Obteniendo lista de vector stores...")
vector_stores = client.vector_stores.list()
if not vector_stores.data:
print("No se encontraron vector stores para eliminar.")
return
total = len(vector_stores.data)
print(f"Se encontraron {total} vector stores.")
# Confirmación de seguridad
confirmacion = input(f"\n⚠️ ADVERTENCIA: Esto eliminará TODOS los {total} vector stores de tu cuenta.\n"
"Esta operación es IRREVERSIBLE.\n"
"Escribe 'ELIMINAR TODO' para confirmar: ")
if confirmacion != "ELIMINAR TODO":
print("Operación cancelada.")
return
print(f"\nEliminando {total} vector stores...")
eliminados = 0
errores = 0
for i, vs in enumerate(vector_stores.data, 1):
try:
print(f"[{i}/{total}] Eliminando vector store: {vs.id}")
if vs.name:
print(f" Nombre: {vs.name}")
# Eliminar el vector store
response = client.vector_stores.delete(vector_store_id=vs.id)
if hasattr(response, 'deleted') and response.deleted:
eliminados += 1
print(f" ✅ Eliminado exitosamente")
else:
print(f" ❌ No se pudo confirmar la eliminación")
errores += 1
# Pequeña pausa para evitar sobrecarga de la API
time.sleep(0.5)
except Exception as e:
print(f" ❌ Error al eliminar {vs.id}: {e}")
errores += 1
print(f"\n📊 Resumen:")
print(f" Vector stores eliminados: {eliminados}")
print(f" Errores: {errores}")
print(f" Total procesados: {eliminados + errores}")
except Exception as e:
print(f"Error general: {e}")
# Ejecutar la función
eliminar_todos_los_vector_stores()
# LISTAMOS AHORA TODOS LOS FILES
from datetime import datetime
def listar_archivos():
"""
Lista todos los archivos almacenados en tu cuenta OpenAI
"""
try:
# Obtener lista de todos los archivos
print("Obteniendo lista de archivos...")
files = client.files.list()
if not files.data:
print("No se encontraron archivos en tu cuenta.")
return
total = len(files.data)
print(f"Se encontraron {total} archivos:")
print("=" * 80)
for i, file in enumerate(files.data, 1):
# Convertir timestamp a fecha legible
created_date = datetime.fromtimestamp(file.created_at).strftime("%Y-%m-%d %H:%M:%S")
size_mb = file.bytes / (1024 * 1024) if file.bytes > 0 else 0
print(f"{i}. Archivo:")
print(f" ID: {file.id}")
print(f" Nombre: {file.filename}")
print(f" Propósito: {file.purpose}")
print(f" Creado: {created_date}")
print(f" Tamaño: {file.bytes} bytes ({size_mb:.2f} MB)")
print(f" Estado: {getattr(file, 'status', 'N/A')}")
print("-" * 80)
except Exception as e:
print(f"Error al obtener archivos: {e}")
# Ejecutar la función
listar_archivos()
#Ahora un código para borrar los ficheros
from openai import OpenAI
from datetime import datetime, timedelta
import time
def eliminar_archivos_avanzado():
"""
Versión avanzada que permite filtrar por propósito, fecha, etc.
"""
try:
# Obtener todos los archivos
files = client.files.list()
if not files.data:
print("No se encontraron archivos.")
return
print(f"Se encontraron {len(files.data)} archivos:")
print("=" * 80)
# Mostrar información detallada agrupada por propósito
archivos_por_proposito = {}
for file in files.data:
purpose = file.purpose
if purpose not in archivos_por_proposito:
archivos_por_proposito[purpose] = []
archivos_por_proposito[purpose].append(file)
for purpose, file_list in archivos_por_proposito.items():
total_size = sum(f.bytes for f in file_list)
size_mb = total_size / (1024 * 1024)
print(f"📁 {purpose.upper()}: {len(file_list)} archivos ({size_mb:.2f} MB)")
for file in file_list[:3]: # Mostrar solo los primeros 3
created_date = datetime.fromtimestamp(file.created_at)
print(f" • {file.filename} - {created_date.strftime('%Y-%m-%d')}")
if len(file_list) > 3:
print(f" ... y {len(file_list) - 3} archivos más")
print()
print("\nOpciones de eliminación:")
print("1. Eliminar TODOS los archivos")
print("2. Eliminar archivos por propósito específico")
print("3. Eliminar archivos más antiguos que X días")
print("4. Eliminar archivos de un tamaño específico")
print("5. Cancelar")
opcion = input("\nSelecciona una opción (1-5): ")
if opcion == "1":
eliminar_todos(files.data)
elif opcion == "2":
eliminar_por_proposito(archivos_por_proposito)
elif opcion == "3":
eliminar_por_fecha(files.data)
elif opcion == "4":
eliminar_por_tamaño(files.data)
else:
print("Operación cancelada.")
except Exception as e:
print(f"Error: {e}")
def eliminar_todos(files):
"""Elimina todos los archivos"""
confirmacion = input(f"\n⚠️ Confirma que quieres eliminar TODOS los {len(files)} archivos.\n"
"Escribe 'SI ELIMINAR TODO': ")
if confirmacion == "SI ELIMINAR TODO":
procesar_eliminacion(files)
else:
print("Cancelado.")
def eliminar_por_proposito(archivos_por_proposito):
"""Elimina archivos de un propósito específico"""
print("\nPropósitos disponibles:")
propositos = list(archivos_por_proposito.keys())
for i, purpose in enumerate(propositos, 1):
count = len(archivos_por_proposito[purpose])
print(f"{i}. {purpose} ({count} archivos)")
try:
seleccion = int(input("\nSelecciona el número del propósito: ")) - 1
if 0 <= seleccion < len(propositos):
purpose_elegido = propositos[seleccion]
archivos_elegidos = archivos_por_proposito[purpose_elegido]
print(f"\nSe eliminarán {len(archivos_elegidos)} archivos con propósito '{purpose_elegido}':")
for file in archivos_elegidos:
print(f" - {file.filename} ({file.id})")
confirmacion = input(f"\nConfirmar eliminación? (si/no): ")
if confirmacion.lower() == 'si':
procesar_eliminacion(archivos_elegidos)
else:
print("Selección inválida.")
except ValueError:
print("Por favor, ingresa un número válido.")
def eliminar_por_fecha(files):
"""Elimina archivos más antiguos que X días"""
try:
dias = int(input("Eliminar archivos más antiguos que cuántos días? "))
fecha_limite = datetime.now() - timedelta(days=dias)
antiguos = [f for f in files
if datetime.fromtimestamp(f.created_at) < fecha_limite]
if not antiguos:
print(f"No hay archivos más antiguos que {dias} días.")
return
print(f"Se eliminarán {len(antiguos)} archivos más antiguos que {dias} días:")
for file in antiguos:
fecha = datetime.fromtimestamp(file.created_at).strftime('%Y-%m-%d')
print(f" - {file.filename} - {fecha}")
confirmacion = input(f"\nConfirmar eliminación? (si/no): ")
if confirmacion.lower() == 'si':
procesar_eliminacion(antiguos)
except ValueError:
print("Por favor, ingresa un número válido de días.")
def eliminar_por_tamaño(files):
"""Elimina archivos basado en criterios de tamaño"""
print("\nOpciones de tamaño:")
print("1. Archivos mayores a X MB")
print("2. Archivos menores a X MB")
print("3. Archivos de 0 bytes (vacíos)")
opcion = input("Selecciona una opción (1-3): ")
if opcion == "1":
try:
mb_limite = float(input("Eliminar archivos mayores a cuántos MB? "))
bytes_limite = mb_limite * 1024 * 1024
grandes = [f for f in files if f.bytes > bytes_limite]
if grandes:
print(f"Se eliminarán {len(grandes)} archivos mayores a {mb_limite} MB:")
for file in grandes:
size_mb = file.bytes / (1024 * 1024)
print(f" - {file.filename} ({size_mb:.2f} MB)")
confirmacion = input("\nConfirmar eliminación? (si/no): ")
if confirmacion.lower() == 'si':
procesar_eliminacion(grandes)
else:
print(f"No hay archivos mayores a {mb_limite} MB.")
except ValueError:
print("Por favor, ingresa un número válido.")
elif opcion == "3":
vacios = [f for f in files if f.bytes == 0]
if vacios:
print(f"Se eliminarán {len(vacios)} archivos vacíos:")
for file in vacios:
print(f" - {file.filename}")
confirmacion = input("\nConfirmar eliminación? (si/no): ")
if confirmacion.lower() == 'si':
procesar_eliminacion(vacios)
else:
print("No hay archivos vacíos.")
def procesar_eliminacion(archivos_a_eliminar):
"""Procesa la eliminación de los archivos seleccionados"""
total = len(archivos_a_eliminar)
eliminados = 0
errores = 0
print(f"\nEliminando {total} archivos...")
for i, file in enumerate(archivos_a_eliminar, 1):
try:
print(f"[{i}/{total}] Eliminando: {file.filename}")
response = client.files.delete(file.id)
if hasattr(response, 'deleted') and response.deleted:
eliminados += 1
print(f" ✅ Eliminado")
else:
errores += 1
print(f" ❌ Error en la eliminación")
# Pausa para no sobrecargar la API
time.sleep(0.2)
except Exception as e:
errores += 1
print(f" ❌ Error: {e}")
print(f"\n📊 Resultado final:")
print(f" Eliminados exitosamente: {eliminados}")
print(f" Errores: {errores}")
# Ejecutar la versión avanzada
eliminar_archivos_avanzado()
11.5. Structred Outputs#
Los Structured Outputs son una funcionalidad que asegura que las salidas del modelo cumplan exactamente con los esquemas JSON Schema proporcionados por el desarrollador. A diferencia del modo JSON tradicional, esta característica garantiza el cumplimiento del esquema al 100%. También puede decirse que los *Structured Output es una capacidad reciente de la API de OpenAI que permite que los modelos generen salidas que cumplan exactamente un esquema JSON definido por el desarrollador. Es decir, en vez de depender de que el modelo “imite” un formato, podemos forzar que la salida obedezca una estructura dada.
OpenAI lo presenta como una mejora respecto al “JSON mode” anterior: con Structured Outputs, el modelo garantiza que el formato siga el esquema proporcionado.
Esto se logra mediante decodificación con restricciones (constrained decoding), es decir, el modelo no puede salirse de la gramática/estructura permitida.
11.6. Bneficios y casos de uso.#
Algunos de los beneficios:
Fiabilidad en la salida: elimina muchos errores de formato.
Facilidad para integrarse con sistemas que esperan datos estructurados (bases de datos, APIs, frontends).
Menor necesidad de “parsing” manual o correcciones posteriores.
Permite separar la lógica de razonamiento del “empaquetado” del resultado.
Compatible con llamadas a funciones (“tool calling”) para hacer flujos más robustos.
Casos de uso típicos:
Extracción de datos de documentos (por ejemplo: nombres, fechas, direcciones).
Respuestas de APIs conversacionales donde se necesita un formato predecible.
Automatización de flujos multi-paso con agentes que llaman funciones internamente.
Generación de interfaces dinámicas basadas en la intención del usuario (por ejemplo: generar un formulario JSON a partir de la consulta).
11.7. Modelos compatibles:#
Los Structured Outputs están disponibles en los siguientes modelos :
gpt-4o-2024-08-06 (más reciente)
gpt-4o-mini
gpt-4o-mini-2024-07-18
Modelos fine-tuned basados en estos
11.8. Cómo habilitar Structured Outputs.#
Hay dos modos principales de usarlo:
11.8.1. Usando response_format + JSON Schema.#
Puedes pedirle al modelo que responda bajo un esquema JSON concreto, pasando un objeto response_format. Este objeto contiene un tipo “json_schema” y la especificación del esquema JSON que el modelo debe obedecer.
Por ejemplo, en una petición HTTP (o vía SDK):
{
"model": "gpt-4o-2024-08-06",
"messages": [
{ "role": "system", "content": "..." },
{ "role": "user", "content": "..." }
],
"response_format": {
"type": "json_schema",
"json_schema": {
"name": "mi_esquema",
"schema": {
"type": "object",
"properties": {
"campo1": { "type": "string" },
"campo2": { "type": "integer" }
},
"required": ["campo1", "campo2"]
}
}
}
}
Cuando haces esto, el modelo garantiza que la salida será un JSON válido que respete ese esquema (o fallará con un rechazo/refusal).
Importante: esta funcionalidad (con response_format) está disponible en modelos como gpt-4o-mini y gpt-4o-2024-08-06 y sus fine-tunes basados en ellos.
11.8.2. Usando llamadas a funciones (tool calling) con strict: true#
Otra forma poderosa es usar la funcionalidad de function calling (herramientas) de la API, combinada con strict: true en la definición de la función. De esta forma, cuando el modelo “llama” a la función generando argumentos, esos argumentos deben ajustarse al esquema de la función. Por ejemplo, defines una función con parámetros estructurados:
from pydantic import BaseModel
class WeatherQuery(BaseModel):
location: str
date: str
tools = [
openai.pydantic_function_tool(WeatherQuery, strict=True)
]
response = client.chat.completions.create(
model="gpt-4o-2024-08-06",
messages=[...],
tools=tools
)
El modelo generará una llamada a esa función con argumentos que satisfacen el esquema.
Advertencia: no funciona bien si se permiten llamadas paralelas (parallel tool calls). Cuando se usa strict: true, se recomienda desactivar paralelismo.
11.8.3. Ejemplos prácticos:#
Supongamos que queremos que el modelo clasifique el sentimiento de una reseña como “positive”, “negative” o “neutral”, y que la salida sea:
{
"sentiment": "positive"
}
from pydantic import BaseModel
from typing import Literal
from openai import OpenAI
class SentimentResponse(BaseModel):
sentiment: Literal["positive", "negative", "neutral"]
#client = OpenAI()
response = client.chat.completions.parse(
model="gpt-4o-2024-08-06",
messages=[
{"role": "system", "content": "Eres un clasificador de sentimiento."},
{"role": "user", "content": "The food was amazing but the room was small."}
],
response_format=SentimentResponse
)
print(response.choices[0].message.content)
{"sentiment":"neutral"}
11.8.3.1. Resolver un problema matemático.#
Imagina que quieres que el modelo devuelva una serie de pasos para resolver un problema:
El esquema podría ser:
{
"steps": [
{
"explanation": "texto explicativo",
"output": "resultado en esa etapa"
}
],
"final_answer": "respuesta final"
}
class Step(BaseModel):
explanation: str
output: str
class MathReasoning(BaseModel):
steps: list[Step]
final_answer: str
response = client.chat.completions.parse(
model="gpt-4o-2024-08-06",
messages=[...],
response_format=MathReasoning
)
El modelo devolverá un objeto con la propiedad steps (array de objetos con explanation y output) y el campo final_answer.
Veamos un ejemplo básico con Pydantic
from pydantic import BaseModel
from typing import List
class EventoCalendario(BaseModel):
nombre: str
fecha: str
participantes: List[str]
# Usando la API Responses
response = client.responses.parse(
model="gpt-4o-2024-08-06",
input=[
{"role": "system", "content": "Extrae la información del evento."},
{
"role": "user",
"content": "Ana y Bob van a una feria de ciencias el viernes."
}
],
text_format=EventoCalendario,
)
evento = response.output_parsed
print(evento.nombre) # Acceso tipado al resultado
Feria de Ciencias
print(evento)
EventoCalendario(nombre='Feria de Ciencias', fecha='Viernes', participantes=['Ana', 'Bob'])
A continuación vemos un ejemplo con curl y JSON Schema
curl https://api.openai.com/v1/responses \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-4o-2024-08-06",
"input": [
{
"role": "system",
"content": "Eres un tutor de matemáticas. Guía al usuario paso a paso."
},
{
"role": "user",
"content": "¿cómo puedo resolver 8x + 7 = -23?"
}
],
"text": {
"format": {
"type": "json_schema",
"name": "razonamiento_matematico",
"schema": {
"type": "object",
"properties": {
"pasos": {
"type": "array",
"items": {
"type": "object",
"properties": {
"explicacion": { "type": "string" },
"resultado": { "type": "string" }
},
"required": ["explicacion", "resultado"],
"additionalProperties": false
}
},
"respuesta_final": { "type": "string" }
},
"required": ["pasos", "respuesta_final"],
"additionalProperties": false
},
"strict": true
}
}
}'
Otro ejemplo de un profesor de matemáticas:
from pydantic import BaseModel
from typing import List
class Paso(BaseModel):
explicacion: str
resultado: str
class RazonamientoMatematico(BaseModel):
pasos: List[Paso]
respuesta_final: str
response = client.responses.parse(
model="gpt-4o-2024-08-06",
input=[
{
"role": "system",
"content": "Eres un tutor de matemáticas. Guía al usuario paso a paso."
},
{"role": "user", "content": "¿cómo puedo resolver 8x + 7 = -23?"}
],
text_format=RazonamientoMatematico,
)
razonamiento = response.output_parsed
for paso in razonamiento.pasos:
print(f"Paso: {paso.explicacion}")
print(f"Resultado: {paso.resultado}")
print(f"Respuesta final: {razonamiento.respuesta_final}")
Paso: Comienza aislando el término que contiene la variable. Restamos 7 de ambos lados de la ecuación para eliminar el 7 de la izquierda.
Resultado: 8x + 7 - 7 = -23 - 7
Paso: Simplifica ambos lados de la ecuación después de restar.
Resultado: 8x = -30
Paso: Ahora, resuelve para x dividiendo ambos lados de la ecuación por 8.
Resultado: 8x / 8 = -30 / 8
Paso: Simplifica la fracción en el lado derecho de la ecuación.
Resultado: x = -15/4 o x = -3.75
Respuesta final: x = -3.75
Extracción de datos estructurados
from pydantic import BaseModel
from typing import List
class ArticuloInvestigacion(BaseModel):
titulo: str
autores: List[str]
resumen: str
palabras_clave: List[str]
response = client.responses.parse(
model="gpt-4o-2024-08-06",
input=[
{
"role": "system",
"content": "Eres experto en extracción de datos estructurados. Convierte el texto no estructurado de un artículo de investigación en la estructura dada."
},
{
"role": "user",
"content": "Texto del artículo de investigación aquí..."
}
],
text_format=ArticuloInvestigacion,
)
articulo = response.output_parsed
print(f"Título: {articulo.titulo}")
print(f"Autores: {', '.join(articulo.autores)}")
Título: Impacto de la Nutrición en el Desarrollo Cognitivo Infantil: Un Estudio Longitudinal
Autores: Dra. Ana López, Dr. Carlos Méndez, Dra. Lucía García
Generación de Interfaces de Usuario
from pydantic import BaseModel
from typing import List
from enum import Enum
class TipoUI(str, Enum):
div = "div"
boton = "button"
header = "header"
seccion = "section"
campo = "field"
formulario = "form"
class Atributo(BaseModel):
nombre: str
valor: str
class ComponenteUI(BaseModel):
tipo: TipoUI
etiqueta: str
hijos: List['ComponenteUI']
atributos: List[Atributo]
ComponenteUI.model_rebuild() # Necesario para tipos recursivos
response = client.responses.parse(
model="gpt-4o-2024-08-06",
input=[
{
"role": "system",
"content": "Eres un generador de UI. Convierte la entrada del usuario en una UI."
},
{"role": "user", "content": "Crea un formulario de perfil de usuario"}
],
text_format=ComponenteUI,
)
ui = response.output_parsed
Sistema de Moderación de Contenido
from pydantic import BaseModel
from typing import Optional
from enum import Enum
class CategoriaViolacion(str, Enum):
violencia = "violence"
sexual = "sexual"
autolesion = "self_harm"
class ComplianceContenido(BaseModel):
es_violacion: bool
categoria: Optional[CategoriaViolacion]
explicacion_si_viola: Optional[str]
response = client.responses.parse(
model="gpt-4o-2024-08-06",
input=[
{
"role": "system",
"content": "Determina si la entrada del usuario viola directrices específicas y explica si las viola."
},
{
"role": "user",
"content": "¿Cómo me preparo para una entrevista de trabajo?"
}
],
text_format=ComplianceContenido,
)
compliance = response.output_parsed
#### Manejo de rechazos y errores
Gestión de Rechazos de Seguridad
response = client.responses.parse(
model="gpt-4o-2024-08-06",
input=[
{"role": "system", "content": "Responde al usuario de forma útil."},
{"role": "user", "content": "Contenido potencialmente problemático"}
],
text_format=MiEsquema,
)
# Verificar si hubo rechazo por seguridad
if hasattr(response, 'refusal') and response.refusal:
print(f"Solicitud rechazada: {response.refusal}")
else:
resultado = response.output_parsed
# Procesar resultado normal
Manejo de Errores Comunes
try:
response = client.responses.parse(
model="gpt-4o-2024-08-06",
input=mensajes,
text_format=MiEsquema,
)
if response.output_parsed:
datos = response.output_parsed
# Procesar datos exitosos
else:
print("No se pudo parsear la respuesta")
except Exception as e:
print(f"Error en la llamada a la API: {e}")
11.9. Caso de uso: Generación de test#
En este apartado vamos a utilizar diversas herramientas que nos proporciona la API de OpenAI para obtener código que nos genere una serie de preguntas de tipo test con cuatro posibles respuestas y solo una de ellas la verdadera.
Para proceder a conseguir esto, vamos a disponer de dos ficheros de tipo PDF denominados Tema_2_Mortalidad.pdf y Tema_3_Natalidad.pdf, situados en la misma carpeta donde se encuentra el código y que nos van a servir como referencia para el desarrollo de este apartado.
Lo primero que debemos hacer es subir estos ficheros a la plataforma de OpenAI para que los podamos ver en su Dashboard. Para conseguir esto lo hacemos de la siguiente manera (ver apartado anterior: La API de Files): (ver esta referencia )
# Esta sería una forma de hacerlo para cada uno de los ficheros
from openai import OpenAI
# Recordemos que en un blok anterior ya hemos creado el cliente
#file = client.files.create(
# file=open("Tema_2_Mortalidad.pdf", "rb"),
# purpose="assistants",
# expires_after={
# "anchor": "created_at",
# "seconds": 4000
}
)
# Pero si queremos subir los dos con un sólo código lo hacemos de la siguiente manera
file_paths = ["Tema_2_Mortalidad.pdf", "Tema_3_Natalidad.pdf"]
file_ids = [] # Para guardar IDs si los necesitas después
for path in file_paths:
uploaded_file = client.files.create(
file = open(path,"rb"),
purpose = "assistants" # Para uso con assistants/tools/vector stores
)
file_ids.append(uploaded_file.id)
print(f"Archivo subido: {path}")
print(f" ID: {uploaded_file.id}")
print(f" Filename: {uploaded_file.filename}")
print(f" Bytes: {uploaded_file.bytes}\n")
print("Ambos archivos subidos exitosamente. IDs:", file_ids)
Archivo subido: Tema_2_Mortalidad.pdf
ID: file-FFoSFbTCe1jTuxXLhE13Vq
Filename: Tema_2_Mortalidad.pdf
Bytes: 1057614
Archivo subido: Tema_3_Natalidad.pdf
ID: file-CFAhZ6STeupLYfknMKBctd
Filename: Tema_3_Natalidad.pdf
Bytes: 692116
Ambos archivos subidos exitosamente. IDs: ['file-FFoSFbTCe1jTuxXLhE13Vq', 'file-CFAhZ6STeupLYfknMKBctd']
Si ahora nos vamos al Dashboard de OpenAi y elegimos “Storage” como opción del menú, podemos ver estos dos archivos. Hay que tener en cuenta que por la utilización de los vestor stores que usaremos más adelante OpenAi cobra por ello, aunque tiene una parte gratuita (en el momento de redactar estas líneas). En concreto:
En OpenAI, mantener archivos subidos en el endpoint Files no tiene coste de almacenamiento publicado; el cargo aparece cuando esos archivos se añaden a un vector store, que cuesta 0,10 USD por GB de almacenamiento vectorial al día con el primer GB gratis.
Archivos en Files:
La tabla oficial de precios no publica ninguna tarifa por “almacenar” archivos en el endpoint Files; los cargos publicados para documentos aparecen cuando se usa File Search/Vector Stores, no por el mero hecho de subirlos.
En la práctica, la comunidad y documentación informal confirman que puedes mantener archivos subidos sin facturación por almacenamiento, y los costes empiezan al procesarlos en Vector Stores o usar herramientas sobre ellos.
Vector store.
El almacenamiento vectorial cuesta 0,10 USD por GB al día, con 1 GB gratuito de almacenamiento vectorial por cuenta, aplicándose al tamaño procesado (fragmentos + embeddings) que el sistema mantiene para búsqueda. Otros cargos relacionados.
Llamadas a la herramienta de File Search cuando se usa via Responses API tienen un coste de 2,50 USD por 2.000 llamadas, además de los tokens del modelo para el contenido recuperado.
Los “search content tokens” que se inyectan al modelo desde el índice se cobran a las tarifas de tokens del modelo elegido.
Consideraciones útiles.
No hay “doble pago” por tener un archivo en Files y además en un vector store; el cargo relevante es el del vector store y, si aplica, el de llamadas a File Search via Responses.
Si adjuntas el mismo archivo a varios vector stores, el almacenamiento vectorial se factura por cada vector store de forma independiente.
11.9.1. Cración de un vector store.#
Una vez subidos esos ficheros a la plataforma de OpenAI, vamos a crear un vector store donde posteriormente vamos a almacenar los embedings de esos dos ficheros. A este vector store, lo vamos a llamar “almacenamiento”.
vector_store = client.vector_stores.create(
name="almacenamiento"
)
print(vector_store)
VectorStore(id='vs_690c2e2f2e608191be88de11bea3c73e', created_at=1762405935, file_counts=FileCounts(cancelled=0, completed=0, failed=0, in_progress=0, total=0), last_active_at=1762405935, metadata={}, name='almacenamiento', object='vector_store', status='completed', usage_bytes=0, expires_after=None, expires_at=None, description=None)
Este vector store que acabamos de crear, lo podemos ver en el Dashboard de OpenAI, en el mismo sitio que hemos visto los Files anteriores, pero haciendo clock en la solapa “Vector stores”.
Bien una vez creado este vector stores, que no es más que un lugar de almacenamiento, ahora debemos cargar los dos ficheros anteriores en el vector store “almacenamiento”, creado anteriormente. La API que rige esto la podemos ver en este enlace .
Es muy importante tener en cuenta que para procesos posteriores relacionados con búsquedas es muy importante definir metadatos con la opción atributes de esta clase: Veamos cómo hacemos esto :
# obtenemos el ID del vector store creado anteriomente
vector_store_id= vector_store.id
vector_store_file_ids = [] # Para trackear
#para cada elemento FILE identificadi por su ID
# Recordar que file_ids es una lista de ID de los Files creados anteriormente
# Lo hacemos para el primer FILe
vector_store_file =client.vector_stores.files.create(
vector_store_id=vector_store_id,
file_id=file_ids[0],
attributes={
"materia":"Demografia",
"Tema":"2"
}
)
vector_store_file_ids.append(vector_store_file.id)
print(f"Archivo {file_id} adjuntado: vector_store_file_id {vector_store_file.id}, status inicial: {vector_store_file.status}")
# Lo hacemos para el segundo FILe
vector_store_file =client.vector_stores.files.create(
vector_store_id=vector_store_id,
file_id=file_ids[1],
attributes={
"materia":"Demografia",
"Tema":"3"
}
)
vector_store_file_ids.append(vector_store_file.id)
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In[15], line 17
8 vector_store_file =client.vector_stores.files.create(
9 vector_store_id=vector_store_id,
10 file_id=file_ids[0],
(...)
14 }
15 )
16 vector_store_file_ids.append(vector_store_file.id)
---> 17 print(f"Archivo {file_id} adjuntado: vector_store_file_id {vector_store_file.id}, status inicial: {vector_store_file.status}")
19 # Lo hacemos para el segundo FILe
20 vector_store_file =client.vector_stores.files.create(
21 vector_store_id=vector_store_id,
22 file_id=file_ids[1],
(...)
26 }
27 )
NameError: name 'file_id' is not defined
print(f"Archivo {file_ids} adjuntado: vector_store_file_id {vector_store_file.id}, status inicial: {vector_store_file.status}")
Archivo ['file-FFoSFbTCe1jTuxXLhE13Vq', 'file-CFAhZ6STeupLYfknMKBctd'] adjuntado: vector_store_file_id file-FFoSFbTCe1jTuxXLhE13Vq, status inicial: in_progress
# Paso 3: Pollear status para cada vector store file (opcional pero recomendado)
for vsf_id, file_id in zip(vector_store_file_ids, file_ids):
while True:
vsf = client.vector_stores.files.retrieve(
vector_store_id=vector_store_id,
file_id=vsf_id
)
print(f"Status de {file_id} (vsf_id: {vsf_id}): {vsf.status}")
if vsf.status == "completed":
break
elif vsf.status == "failed":
print(f"Error procesando {file_id}: {vsf.last_error}")
break
time.sleep(5)
print("Todos los archivos procesados.")
Status de file-FFoSFbTCe1jTuxXLhE13Vq (vsf_id: file-FFoSFbTCe1jTuxXLhE13Vq): completed
Todos los archivos procesados.
Ahora que ya tenemos subidos todos los elementos que necesitamos, podemos crear las preguntas del test que necesitamos
from openai import OpenAI
from pydantic import BaseModel, Field
from typing import List
#client = OpenAI(api_key="tu_api_key") # Ya lo tenemos creado de pasos anteriores
# Schema JSON para structured outputs (mismo que antes)
class Option(BaseModel):
text: str = Field(..., description="Una de las 4 opciones posibles")
class MCQ(BaseModel):
question: str = Field(..., description="La pregunta de opción múltiple")
options: List[Option] = Field(..., description="Lista de 4 opciones (A, B, C, D)")
correct_answer: int = Field(..., description="Índice de la respuesta correcta (0-3 para A-D)")
explanation: str = Field(..., description="Explicación breve de por qué es correcta")
class MCQsResponse(BaseModel):
questions: List[MCQ] = Field(..., description="Lista de exactamente 10 preguntas generadas del vector store")
# Llamada corregida a Responses API
response = client.responses.parse(
model="gpt-4o-mini", # O "gpt-4o" para precisión
input="Analiza el contenido de los archivos en el vector store y genera exactamente 5 preguntas de opción múltiple. Cada pregunta debe cubrir temas clave de los documentos, con 4 opciones (A, B, C, D) donde solo una es correcta. Asegúrate de que sean educativas y basadas en hechos del contenido.",
tools=[
{
"type": "file_search",
"vector_store_ids": ["vs_690c2e2f2e608191be88de11bea3c73e"] # ID de tu vector store con los 2 files
}
],
text_format=MCQsResponse # Fuerza salida estructurada
)
response
ParsedResponse[MCQsResponse](id='resp_05043d2df129b7e000690c684226848191a84eb5a239eecf21', created_at=1762420802.0, error=None, incomplete_details=None, instructions=None, metadata={}, model='gpt-4o-mini-2024-07-18', object='response', output=[ResponseFileSearchToolCall(id='fs_05043d2df129b7e000690c684337a88191b595f3b41687ad41', queries=['Principales temas del documento', ' contenido clave del archivo', 'Resumen de los archivos subidos', 'Aspectos destacados de los documentos', 'Puntos importantes en el vector store'], status='completed', type='file_search_call', results=None), ResponseFileSearchToolCall(id='fs_05043d2df129b7e000690c684589188191baf78d3538b0cffb', queries=['mortalidad infantil', 'Tasa de Mortalidad por causas', 'Tablas de mortalidad', 'Análisis de la mortalidad', 'Efectos de envejecimiento en la mortalidad'], status='completed', type='file_search_call', results=None), ResponseFileSearchToolCall(id='fs_05043d2df129b7e000690c684822ec819187f97cdee7c6cdfb', queries=['mortalidad infantil definición', 'tasa de mortalidad', 'tipos de mortalidad', 'esperanza de vida', 'causas de mortalidad'], status='completed', type='file_search_call', results=None), ResponseFileSearchToolCall(id='fs_05043d2df129b7e000690c684a46bc81919ad94ab63d01ffd5', queries=['mortalidad infantil', 'esperanza de vida', 'tasas de mortalidad', 'tablas de mortalidad', 'causas de muerte'], status='completed', type='file_search_call', results=None), ResponseFileSearchToolCall(id='fs_05043d2df129b7e000690c684cf8648191b2871735db8374e3', queries=['Tasa de mortalidad infantil', 'Mortalidad neonatal', 'Esperanza de vida', 'Tablas de mortalidad', 'Causas de mortalidad'], status='completed', type='file_search_call', results=None), ResponseFileSearchToolCall(id='fs_05043d2df129b7e000690c684f520081919abbf06554a51c16', queries=['Mortalidad infantil definición', 'Tasa de mortalidad', 'Espereanza de vida', 'Causas de mortalidad', 'Tablas de mortalidad'], status='completed', type='file_search_call', results=None), ResponseFileSearchToolCall(id='fs_05043d2df129b7e000690c68512e4c8191827fa642de91b090', queries=['esperanza de vida definición', 'tasa de mortalidad infantil', 'análisis de mortalidad infantil', 'tablas de mortalidad', 'mortalidad por causas'], status='completed', type='file_search_call', results=None), ResponseFileSearchToolCall(id='fs_05043d2df129b7e000690c685321688191a74c2bb158745ca3', queries=['mortalidad infantil', 'causas de mortalidad', 'esperanza de vida', 'tablas de mortalidad'], status='completed', type='file_search_call', results=None), ResponseFileSearchToolCall(id='fs_05043d2df129b7e000690c68552734819191a609952ca075dd', queries=['Esperanza de vida en España', 'Causas de mortalidad infantil', 'Mortalidad neonatal y postneonatal', 'Tablas de mortalidad en España', 'Métodos de análisis de mortalidad'], status='completed', type='file_search_call', results=None), ResponseFileSearchToolCall(id='fs_05043d2df129b7e000690c685717ac8191a93e46857146813a', queries=['Esperanza de vida', 'Causas de mortalidad', 'Tasa de mortalidad infantil', 'Mortandad general en España', 'Cohorte de población y mortalidad'], status='completed', type='file_search_call', results=None), ResponseFileSearchToolCall(id='fs_05043d2df129b7e000690c6859b1a48191a81f634428b1ea03', queries=['Tasa de mortalidad infantil', 'Esperanza de vida', 'Tablas de mortalidad', 'Causas de mortalidad'], status='completed', type='file_search_call', results=None), ResponseFileSearchToolCall(id='fs_05043d2df129b7e000690c685c520c819190256259143cbacc', queries=['mortalidad infantil', 'tasa de mortalidad', 'esperanza de vida', 'análisis de mortalidad', 'tablas de mortalidad'], status='completed', type='file_search_call', results=None), ResponseFileSearchToolCall(id='fs_05043d2df129b7e000690c685e72608191a84b354636cd737c', queries=['Evolución de las tasas de mortalidad', 'Causas de mortalidad en España', 'Tasa de mortalidad infantil', 'Esperanza de vida en distintas edades', 'Métodos de análisis de mortalidad'], status='completed', type='file_search_call', results=None), ResponseFileSearchToolCall(id='fs_05043d2df129b7e000690c68606db881918ecf91a4c7e1feac', queries=['temas clave del documento', 'mortalidad infantil', 'esperanza de vida', 'análisis de mortalidad', 'cálculos de tasas de mortalidad'], status='completed', type='file_search_call', results=None), ResponseFileSearchToolCall(id='fs_05043d2df129b7e000690c686256a4819192555d8d36b6d9f2', queries=['concepto de mortalidad infantil', 'tasa de mortalidad', 'esperanza de vida en España', 'mortalidad neonatal', 'causas de defunciones en la infancia'], status='completed', type='file_search_call', results=None), ResponseFileSearchToolCall(id='fs_05043d2df129b7e000690c6864b1c081919681539886c6c64f', queries=['Causas de mortalidad infantil', 'Tasa de mortalidad infantil en España', 'Análisis de mortalidad en España', 'Esperanza de vida', 'Tablas de mortalidad'], status='completed', type='file_search_call', results=None), ResponseFileSearchToolCall(id='fs_05043d2df129b7e000690c68676b408191ba7d78c66f34bfe9', queries=['principales causas de mortalidad', 'mortalidad infantil en España', 'esperanza de vida', 'tablas de mortalidad', 'análisis de tasas de mortalidad'], status='completed', type='file_search_call', results=None), ResponseFileSearchToolCall(id='fs_05043d2df129b7e000690c686a2f988191a29977985993977f', queries=['Esperanza de vida definición', 'Tasa de mortalidad infantil', 'Causas de muerte infantil', 'Tablas de mortalidad en España', 'análisis de mortalidad en diferentes sexos'], status='completed', type='file_search_call', results=None), ResponseFileSearchToolCall(id='fs_05043d2df129b7e000690c686d5bf481918fff4e23b7d138d4', queries=['esperanza de vida', 'tasa de mortalidad infantil', 'tablas de mortalidad', 'mortalidad neonatal', 'análisis de mortalidad', 'causas de mortalidad en España'], status='completed', type='file_search_call', results=None), ResponseFileSearchToolCall(id='fs_05043d2df129b7e000690c68701e3081919280069a6676c945', queries=['Esperanza de vida en España', 'Causas de mortalidad infantil', 'Tasa de mortalidad infantil', 'Tablas de mortalidad en España', 'Métodos de análisis de mortalidad'], status='completed', type='file_search_call', results=None)], parallel_tool_calls=True, temperature=1.0, tool_choice='auto', tools=[FileSearchTool(type='file_search', vector_store_ids=['vs_690c2e2f2e608191be88de11bea3c73e'], filters=None, max_num_results=20, ranking_options=RankingOptions(ranker='auto', score_threshold=0.0))], top_p=1.0, background=False, conversation=None, max_output_tokens=None, max_tool_calls=None, previous_response_id=None, prompt=None, prompt_cache_key=None, reasoning=Reasoning(effort=None, generate_summary=None, summary=None), safety_identifier=None, service_tier='default', status='completed', text=ResponseTextConfig(format=ResponseFormatTextJSONSchemaConfig(name='MCQsResponse', schema_={'$defs': {'MCQ': {'properties': {'question': {'description': 'La pregunta de opción múltiple', 'title': 'Question', 'type': 'string'}, 'options': {'description': 'Lista de 4 opciones (A, B, C, D)', 'items': {'$ref': '#/$defs/Option'}, 'title': 'Options', 'type': 'array'}, 'correct_answer': {'description': 'Índice de la respuesta correcta (0-3 para A-D)', 'title': 'Correct Answer', 'type': 'integer'}, 'explanation': {'description': 'Explicación breve de por qué es correcta', 'title': 'Explanation', 'type': 'string'}}, 'required': ['question', 'options', 'correct_answer', 'explanation'], 'title': 'MCQ', 'type': 'object', 'additionalProperties': False}, 'Option': {'properties': {'text': {'description': 'Una de las 4 opciones posibles', 'title': 'Text', 'type': 'string'}}, 'required': ['text'], 'title': 'Option', 'type': 'object', 'additionalProperties': False}}, 'properties': {'questions': {'description': 'Lista de exactamente 10 preguntas generadas del vector store', 'items': {'$ref': '#/$defs/MCQ'}, 'title': 'Questions', 'type': 'array'}}, 'required': ['questions'], 'title': 'MCQsResponse', 'type': 'object', 'additionalProperties': False}, type='json_schema', description=None, strict=True), verbosity='medium'), top_logprobs=0, truncation='disabled', usage=ResponseUsage(input_tokens=16604, input_tokens_details=InputTokensDetails(cached_tokens=0), output_tokens=901, output_tokens_details=OutputTokensDetails(reasoning_tokens=0), total_tokens=17505), user=None, billing={'payer': 'developer'}, prompt_cache_retention=None, store=True)
# Extrae y muestra las preguntas (igual que antes)
mcqs = response.choices[0].output.parsed
for i, q in enumerate(mcqs.questions, 1):
print(f"Pregunta {i}: {q.question}")
for j, opt in enumerate(q.options):
letter = chr(65 + j) # A, B, C, D
print(f" {letter}. {opt.text}")
correct_letter = chr(65 + q.correct_answer)
print(f" Respuesta correcta: {correct_letter} ({q.options[q.correct_answer].text})")
print(f" Explicación: {q.explanation}\n")