Web scraping con R
Contenido
- Introducción
- Herramientas a tener en cuenta dentro de este campo.
- Utilización de rvest.
- Web scraping con httr
- Web scraping con Rselenium
Introducción
En este post me voy a centrar en una técnica muy utilizada dentro del mundo de Big Data pues permite obtener información de una forma directa de muchos de los sitios web que hoy en día existen dentro de la red de redes. La técnica se denomina “web scraping” usando el término anglosajón utilizado para ello, y consiste básicamente en los siguiente.
Toda página web pose una estructura determinada, identificada por las etiquetas html, xml o bien por las hojas de estilo en cascada denominadas “css”. Pues bien básicamente el método consiste en acceder al contenido de las páginas web y elegir los elementos que nos interesan para bajar esos datos a nuestro sistema y poder trabajar sobre ellos.
Como puede desprenderse la técnica es sumamente interesante y abre la puerta una búsqueda amplia de información y sobre una gran cantidad de materias, amen de poder hacer un seguimiento en el tiempo, sin coste alguno, y de una forma fácil y precisa.
No obstante lo anterior, existe un gran inconveniente a todo lo dicho anteriormente, y básicamente consiste en que hay muchas páginas web, que con la finalidad de controlar estos métodos, disponen de procedimientos automáticos para que cuando se detecte este tipo de herramientas cortan el suministro y te meten en una “lista negra” ( en términos anglosajones también denominada blacklist ) impidiendo su acceso de nuevo, en ciertas ocasiones de manera temporal, mientras que en otras de forma permanente.
Las posibilidades que abre este sistema de explotación de la web son inmensas, ya que con esta información, entre otras muchas otras cosas se podría por ejemplo:
1.- Utilizar la información que proporciona la base de datos IMDB (Bases de datos de películas de internet) como fuente de información para asesorar sobre películas, en base a la puntuación que otras personas han otorgado a las mismas.
2.- Explotar información aparecida en redes sociales, a fin de analizar sentimientos, su evolución y opiniones sobre determinados temas.
3.- Pensar en el potencial existente para el análisis de precios, o búsquedas de productos en páginas como la del Corte Inglés, Amazon, etc, etc, etc.
Herramientas a tener en cuenta dentro de este campo.
Para poder trabajar en esta materia, es necesario tener ciertos conocimientos que a continuación se pasan a exponer.
1.- Inicialmente es preciso conocer que existen una serie de paquetes en R que están especializados en este tipo de búsqueda de información. A continuación se exponen los que más ampliamente se utilizan dentro de este campos:
-
El paquete rvest es uno de los más utilizados, que permite hacer “scrape” sobre páginas web, de una forma ágil, fácil y dinámica. Un tutorial en inglés lo puedes econtrar en este enlace.
-
El paquete httr que facilita un conjunto de herramientas muy útiles para trabajar con páginas web. Un tutorial en inglés lo puedes encontrar en este enlace.
-
El paquete RSelenium. Selenium es un entorno de pruebas de software para aplicaciones basadas en la web y RSelenium es un paquete enfocado para permitir esta tarea desde R. Con este paquete, también se puede tener acceso al contenido de las páginas web, y poder entresacar información de las mismas. Un tutorial en inglés lo puedes encontrar en este enlace.
-
El paquete curl, si bien no es trascendental para esta materia, si permite ejecutar instrucciones del tipo “curl” muy extendidas dentro del mundo linux. Un tutorial en inglés lo puedes encontrar en este enlace.
Además de las librerías anteriores, también es importante, aunque no imprescindible, tener conocimentos sobre la etiquetas HTML y las hojas de estilo en cascada, es decir de CSS, pues gracias a esas etiquetas y al código CSS podremos apuntar a una determinada posición de la página web y extraer la información que precisemos.Existen en internet muchos lugares que pueden hacer luz sobre estas cuestiones, pero la que te indico en este enlace considero que es muy atractiva y fácil de entender para comprender tanto CSS como las etiquetas HTML.
También existen herramientas gratuitas muy interesantes para poder comprender la estructura de una página web y poder interactuar con ella, para entresacar su información. Una primera herramienta es el denominado “selector Gadget” que lo puedes encontrar en este enlace, y que por ejemplo en google chrome lo puedes instalar como una extensión del navegador ( en este enlace puedes ver cómo instalar esas extensiones ).
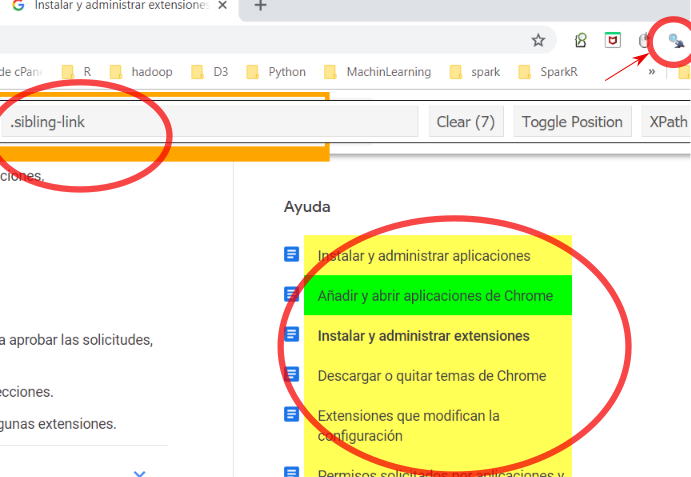
En la figura anterior se muestra el icono en el que hay que hacer click para activar esta utilidad mediante la cual podemos saber el tipo de elemento css y la etiqueta HTML a la que tenemos que hacer referencia para seleccionar la parte correspondiente de la página web.
Otra herramienta para mi mucho más interesante que la indicada anteriormente es la denominada DevTools que la puedes encontrar en este enlace. En google chrome y en Mochila ya viene instalada por defecto. Para que aparezca en google chrome hay que utilizar conjuntamente las siguientes teclas: Ctrl+Mayúscula+I o bien simplemente presionar la tecla F12, y entonces nos aparecerá una imagen similar a la que se muestra en el gráfico inferior.

Con DevTools, puedes perfectamente identificar todos y cada unos de los elementos de la página web, incluso puedes cambiar en el panel de la derecha en modo pruebas para ver cómo queda determinada etiqueta CSS. Esta herramienta es muy poderosa y fácil de manejar por lo que la recomiendo claramente tanto para este tipo de trabajos, como para cualquier otro relacionado con el contenido de las páginas web.
Utilización de rvest.
Vamos a continuación a ver cómo podremos sacar el contenido de una página web para poder interactuar con su contenido. Lo vamos a hacer extrayendo datos desde la siguiente página web: https://www.imdb.com/chart/moviemeter?ref_=nv_mv_mpm.
# Añadir libreria
if (!require("rvest")) install.packages("rvest"); require("rvest")
## Loading required package: rvest
## Loading required package: xml2
#Indicamos la url con la que trabajaremos
url<-"https://www.imdb.com/chart/moviemeter?ref_=nv_mv_mpm"
#Ahora descargamos la página web
pagina<-read_html(url)
# Veamos su estructura
str(pagina)
## List of 2
## $ node:<externalptr>
## $ doc :<externalptr>
## - attr(*, "class")= chr [1:2] "xml_document" "xml_node"
Una vez descargada la página, ya podremos ir extrayendo información de la misma. Con ayuda de DevTools, podremos ver que se puede extraer, entre otras, la siguiente información.
1.- Título. Elemento css class=”titleColumn”
2.- **Año*. Elemento css class=”secondaryInfo”
3.- Posición y cambio en el ranking. Elemento css class=”velocity”
4.- Rating. Elemento css class=”ratingColumn imdbRating”
Bien de acuerdo con los elementos que podremos entresacar, comenzaremos por sacar los títulos de las películas. Para ello, podríamos utilizar el código siguiente:
# Utilizamos el elemento css="titleColumn" para sacar estos títulos
titulos_html=html_nodes(pagina,".titleColumn")
print(head(titulos_html))
## {xml_nodeset (6)}
## [1] <td class="titleColumn">\n \n <a href="/title/tt1502407/?p ...
## [2] <td class="titleColumn">\n \n <a href="/title/tt1727824/?p ...
## [3] <td class="titleColumn">\n \n <a href="/title/tt1517451/?p ...
## [4] <td class="titleColumn">\n \n <a href="/title/tt1270797/?p ...
## [5] <td class="titleColumn">\n \n <a href="/title/tt1213641/?p ...
## [6] <td class="titleColumn">\n \n <a href="/title/tt0077651/?p ...
Como vemos el resultado que se obtiene es la etiqueta completa del documento HTML, si queremos entresacar el texto de la etiqueta, deberemos utilizar el código siguiente:
titulos<-html_text(titulos_html)
head(titulos)
## [1] "\n \n La noche de Halloween\n (2018)\n 1\n(no change)\n\n "
## [2] "\n \n Bohemian Rhapsody\n (2018)\n 2\n(\n\n7)\n\n "
## [3] "\n \n Ha nacido una estrella\n (2018)\n 3\n(\n\n1)\n\n "
## [4] "\n \n Venom\n (2018)\n 4\n(\n\n1)\n\n "
## [5] "\n \n First Man (El primer hombre)\n (2018)\n 5\n(\n\n1)\n\n "
## [6] "\n \n La noche de Halloween\n (1978)\n 6\n(\n\n2)\n\n "
Observamos que el resultado no es el que realmente deseamos, pues nos aparece el título sí pero además mucha más información que entorpece el tratamiento del dato que queremos entresacar.
El motivo de esto lo vemos observando la estructura del documento HTML, pues podemos ver que el título está dentro de una etiqueta que es hija de la class=”titleColumn”. Para resolver esto utilizaremos el código siguiente:
titulos_html=html_nodes(pagina,".titleColumn>a")
titulos<-html_text(titulos_html)
head(titulos)
## [1] "La noche de Halloween" "Bohemian Rhapsody"
## [3] "Ha nacido una estrella" "Venom"
## [5] "First Man (El primer hombre)" "La noche de Halloween"
Con la instrucción “.titleColumn>a” indicamos que tome la clase titleColumn y después la etiqueta hijo de tipo a que cuelga directamente de ella. Si quisiéramos hacer referencia a toda la descendencia (no solo a los hijos) se pondría “.titleColumn a”.
Otra forma de obtener lo anterior pero con pipelines, sería así:
titulos<-pagina%>%html_nodes(".titleColumn>a")%>%html_text()
head(titulos)
## [1] "La noche de Halloween" "Bohemian Rhapsody"
## [3] "Ha nacido una estrella" "Venom"
## [5] "First Man (El primer hombre)" "La noche de Halloween"
El resto de elementos se obtendría de forma muy similar, no obstante veamos a continuación cómo sacar la posición y el cambio de ratting, pues presenta cierto elemento diferenciador respecto a lo hecho en el ejemplo anterior, porque en este caso el string que entresacamos contiene dos elementos, uno es el ranking y el otro es el que indica los puestos que suben o bajan respecto del puestos anterior.
posicion_rating_html<-html_nodes(pagina,".velocity")
position<-html_text(posicion_rating_html)
head(position)
## [1] "1\n(no change)\n" "2\n(\n\n7)\n" "3\n(\n\n1)\n"
## [4] "4\n(\n\n1)\n" "5\n(\n\n1)\n" "6\n(\n\n2)\n"
#Ahora sacamos la posición
#substr(position,1,gregexpr(pattern = "(",position)[[1]])
if (!require("stringr")) install.packages("stringr"); require("stringr")
## Loading required package: stringr
print("Sacamos las posiciones de las peliculas ")
## [1] "Sacamos las posiciones de las peliculas "
as.numeric(substr(position,1,str_locate(position, "\\(")[1]-1))
## [1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23
## [24] 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46
## [47] 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69
## [70] 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92
## [93] 93 94 95 96 97 98 99 10
print("sacamos el movimiento de puesto")
## [1] "sacamos el movimiento de puesto"
head(substr(position,str_locate(position, "\\(")[1],length(position) ))
## [1] "(no change)\n" "(\n\n7)\n" "(\n\n1)\n" "(\n\n1)\n"
## [5] "(\n\n1)\n" "(\n\n2)\n"
El sentido del cambio del puesto es difícil sacarlo, pues si te fijas en la página web ese sentido está indicado con una flecha hacia arriba o hacia abajo, y eso no tiene transcripción literal.
Por último vamos a ver una propiedad muy importante del paquete rvest, es el método “html_table”, ya que con él, una etiqueta “table” de html, se convierte en un dataframe de r. Veamos un ejemplo, en este caso de la url “http://www.bolsamadrid.es/esp/aspx/Mercados/Precios.aspx?indice=ESI100000000”
url<-"http://www.bolsamadrid.es/esp/aspx/Mercados/Precios.aspx?indice=ESI100000000"
pagina2<-read_html(url)
tabla_nodo<-html_nodes(pagina2,".TblPort")
# En esa página web hay al menos dos tablas. Cogemos la segunda
tabla<-html_table(tabla_nodo[[2]])
head(tabla)
## Nombre Últ. % Dif. Máx. Mín. Volumen
## 1 ACCIONA 74,5800 0,00 75,6400 74,1400 93.752
## 2 ACERINOX 9,8680 0,59 9,9480 9,6900 2.494.281
## 3 ACS 33,1100 0,79 33,8100 33,1100 920.226
## 4 AENA 141,1500 0,82 143,0000 139,1000 247.470
## 5 AMADEUS 71,1800 1,98 71,6400 69,9200 1.750.408
## 6 ARCELORMIT. 22,0000 2,25 22,2000 21,7100 385.407
## Efectivo (miles \200) Fecha Hora
## 1 6.997,50 31/10/2018 Cierre
## 2 24.580,49 31/10/2018 Cierre
## 3 30.538,86 31/10/2018 Cierre
## 4 34.909,35 31/10/2018 Cierre
## 5 124.027,12 31/10/2018 Cierre
## 6 8.477,89 31/10/2018 Cierre
Web scraping con httr
El paquete httr contiene clases muy útiles para interactuar con páginas web, por ese motivo es un paquete muy útil para el scraping de páginas web. Es un paquete con un enfoque centrado sobre todo en el estudio de los contenidos de las páginas web. En los ejemplos que a continuación voy a poner se va a utilizar una dirección web de venta de viviendas entre particulares, y en la provincia de Valladolid. En concreto la dirección web que voy a utilizar es la siguiente: https://www.idealista.com/venta-viviendas/valladolid-provincia/. Para leerla se utilizará la siguiente instrucción.
if (!require("httr")) install.packages("httr"); require("httr")
## Loading required package: httr
url<-"https://www.idealista.com/venta-viviendas/valladolid-provincia/"
pisos_web<-GET(url)
Una vez obtenido el objeto que devuelve la instrucción GET, podemos obtener otro tipo de información.
print("Las cookies recibidas:")
## [1] "Las cookies recibidas:"
pisos_web$cookies
## domain flag path secure expiration name value
## 1 www.idealista.com FALSE / FALSE 1970-01-01 01:00:01 _pxCaptcha <NA>
print("Valores asociados a los headers de la página")
## [1] "Valores asociados a los headers de la página"
pisos_web$headers
## $server
## [1] "Varnish"
##
## $`retry-after`
## [1] "0"
##
## $`content-length`
## [1] "3885"
##
## $`content-type`
## [1] "text/html"
##
## $`accept-ranges`
## [1] "bytes"
##
## $date
## [1] "Wed, 31 Oct 2018 18:32:29 GMT"
##
## $via
## [1] "1.1 varnish"
##
## $connection
## [1] "close"
##
## $`set-cookie`
## [1] "_pxCaptcha=; Expires=Thu, 01 Jan 1970 00:00:00 GMT; path=/; "
##
## $`x-served-by`
## [1] "cache-cdg20730-CDG"
##
## $`x-cache`
## [1] "MISS"
##
## $`x-cache-hits`
## [1] "0"
##
## attr(,"class")
## [1] "insensitive" "list"
Este paquete tiene muchas opciones interesantes y muy útiles a la hora de trabajar con páginas web. El lector interesado puede encontrar todas sus posibilidades en el tutorial del propio paquete. Aquí y en lo que sigue me voy a centrar en el contenido de este post, es decir en la posibilidad de analizar los contenidos de cara a posibles estudios estadísticos de la materia.
En concreto si se quiere tomar el contenido en bruto, es decir con etiquetas html y código css, se puede obtener de la siguiente manera.
print(content(pisos_web,encoding = "UTF-8"))
## {xml_document}
## <html lang="es">
## [1] <head>\n<meta http-equiv="Content-Type" content="text/html; charset= ...
## [2] <body> <section class="container"><div class="customer-logo-wrapper" ...
Ahora que ya tenemos el contenido de la página web podremos utilizar herramientas ya vistas anteriormente para entresacar la información que precisemos. Por, ejemplo supongamos que queremos extraer el precio de los pisos que figuran en dicha página. Esto lo conseguiremos de la siguiente manera.
if (!require("rvest")) install.packages("rvest"); require("rvest")
nodos<-html_nodes(content(pisos_web,encoding = "UTF-8"),".txt-big")
nodos
## {xml_nodeset (0)}
Como puedes ver en el ejemplo anterior, no se obtiene el resultado deseado y el motivo no es que la instrucción esté mal, sino que la página web, o mejor dicho el sitio web está creado para que no se le puedan hacer consultas de forma automática. Una forma de ver esto es consultando el fichero robots.txt que se encuentra en la raíz de todo sitio web y que en este caso sería la siguiente dirección: https://www.idealista.com/robots.txt. Ahí podemos ver que hay una línea que dice “Disallow: /venta-,,*,” e indica que no se puede acceder con procedimientos automáticos a ese tipo de dirección.
Vamos a intentarlo con otra dirección, en este caso del Banco de España, de donde podremos entresacar las noticias que en dicha página web aparecen.
bde<-GET("https://www.bde.es/bde/es/")
html_text(html_nodes(content(bde),".contentnews a"))
## [1] "Gobernador. Congreso de los Diputados "
## [2] "@BancoDeEspana se estrena en Twitter (145 KB)"
## [3] "La capacidad de financiación de la economía española fue de 2 mm de euros en agosto de 2018, inferior en 0,7 mm a la de un año antes "
## [4] "El crecimiento de la industria FinTech en China, un caso singular "
## [5] "Director General de Economía y Estadística. Conferencia Banco de España-SUERF (708 KB)"
Web scraping con Rselenium
Tal y como podemos encontrar en la wikipedia Selenium es un entorno de pruebas de software para aplicaciones basadas en la web, y Rselenium es un paquete de R que permite conseguir esos objetivos. Se pueden aprovechar las herramientas de ese paquete para hacer también web scraping. A continuación de muestra un ejemplo en el que se entresacan los precios de los coches que aparecen en milanuncios.
if (!require("RSelenium")) install.packages("RSelenium"); require("RSelenium")
## Loading required package: RSelenium
#Creamos el driver remoto
rsd <- rsDriver(browser = "chrome")
## checking Selenium Server versions:
## BEGIN: PREDOWNLOAD
## BEGIN: DOWNLOAD
## BEGIN: POSTDOWNLOAD
## checking chromedriver versions:
## BEGIN: PREDOWNLOAD
## BEGIN: DOWNLOAD
## BEGIN: POSTDOWNLOAD
## checking geckodriver versions:
## BEGIN: PREDOWNLOAD
## BEGIN: DOWNLOAD
## BEGIN: POSTDOWNLOAD
## checking phantomjs versions:
## BEGIN: PREDOWNLOAD
## BEGIN: DOWNLOAD
## BEGIN: POSTDOWNLOAD
## [1] "Connecting to remote server"
## $acceptInsecureCerts
## [1] FALSE
##
## $acceptSslCerts
## [1] FALSE
##
## $applicationCacheEnabled
## [1] FALSE
##
## $browserConnectionEnabled
## [1] FALSE
##
## $browserName
## [1] "chrome"
##
## $chrome
## $chrome$chromedriverVersion
## [1] "70.0.3538.67 (9ab0cfab84ded083718d3a4ff830726efd38869f)"
##
## $chrome$userDataDir
## [1] "C:\\Users\\FRANCI~1\\AppData\\Local\\Temp\\scoped_dir18176_14319"
##
##
## $cssSelectorsEnabled
## [1] TRUE
##
## $databaseEnabled
## [1] FALSE
##
## $`goog:chromeOptions`
## $`goog:chromeOptions`$debuggerAddress
## [1] "localhost:64151"
##
##
## $handlesAlerts
## [1] TRUE
##
## $hasTouchScreen
## [1] FALSE
##
## $javascriptEnabled
## [1] TRUE
##
## $locationContextEnabled
## [1] TRUE
##
## $mobileEmulationEnabled
## [1] FALSE
##
## $nativeEvents
## [1] TRUE
##
## $networkConnectionEnabled
## [1] FALSE
##
## $pageLoadStrategy
## [1] "normal"
##
## $platform
## [1] "Windows NT"
##
## $rotatable
## [1] FALSE
##
## $setWindowRect
## [1] TRUE
##
## $takesHeapSnapshot
## [1] TRUE
##
## $takesScreenshot
## [1] TRUE
##
## $unexpectedAlertBehaviour
## [1] ""
##
## $version
## [1] "70.0.3538.77"
##
## $webStorageEnabled
## [1] TRUE
##
## $webdriver.remote.sessionid
## [1] "7f3a08fb1a0d2a3a408fcfb9008c341e"
##
## $id
## [1] "7f3a08fb1a0d2a3a408fcfb9008c341e"
remDr <- rsd[["client"]]
# Sacamos solo información de cuatro páginas, pues con más lo suele bloquear
for(j in 1:3){
url="https://www.milanuncios.com/coches-de-segunda-mano/?pagina=j"
#Go to your url
remDr$navigate(url)
page <- read_html(remDr$getPageSource()[[1]])
print(page %>% html_nodes(".aditem-price") %>% html_text())
}
## [1] "5\200" "500\200" "2.800\200" "4.500\200" "5.500\200" "3.500\200" "15.000\200"
## [8] "1.000\200" "7.500\200" "2.350\200" "15.000\200" "5.000\200" "5.000\200" "4.499\200"
## [15] "11.500\200" "3.300\200" "3.990\200" "18.900\200" "16.500\200" "31.990\200" "5.700\200"
## [22] "4.999\200" "750\200" "6.999\200"
## [1] "5\200" "500\200" "2.800\200" "4.500\200" "5.500\200" "3.500\200" "15.000\200"
## [8] "1.000\200" "7.500\200" "2.350\200" "15.000\200" "5.000\200" "5.000\200" "4.499\200"
## [15] "11.500\200" "3.300\200" "3.990\200" "18.900\200" "16.500\200" "31.990\200" "5.700\200"
## [22] "4.999\200" "750\200" "6.999\200"
## [1] "5\200" "500\200" "2.800\200" "4.500\200" "5.500\200" "3.500\200" "15.000\200"
## [8] "1.000\200" "7.500\200" "2.350\200" "15.000\200" "5.000\200" "5.000\200" "4.499\200"
## [15] "11.500\200" "3.300\200" "3.990\200" "18.900\200" "16.500\200" "31.990\200" "5.700\200"
## [22] "4.999\200" "750\200" "6.999\200"
Como has podido comprobar con la instrucción “rsd <- rsDriver(browser = “chrome”)” y la siguiente te levanta el navegador google chrome ( ojo, para este ejemplo necesitas tenerlo instalado ). Es preciso matizar que estas páginas están configuradas para que si se lanzan muchas consultas, se bloquee la petición de una forma temporal. Yo he podido comprobar que después una media hora aproximadamente se pueda volver a realizar la petición y te facilita la respuesta correspondiente como en este caso.
Con esto finaliza la exposición de esta materia, que espero te pueda servir de gran utilidad para todos los trabajos que sobre ello quieras realizar. Si quieres ver cómo enfocar el tema de web scaping con python en este otro post te lo explico.