Introducción a Pandas
Contenido
- Introducción
- Datos de tipo Series
- Datos de tipo DataFrame
- Datos de tipo Panel
- Trabajando con Pandas
- Indexar y seleccionar datos
- Pipeline en Pandas
- Propiedad GroupBy
- Gráficos con Pandas
Introducción
En post’s anteriores ya hemos hecho una presentación el paquete de Python ampliamente utilizado por la comunidad de machine learning denominado Pandas. En esta ocasión vamos a entrar con un poco más de detalle en la utilización de esta herramienta.
Antes de nada decir que el paquete Pandas es un producto de código abierto y por lo tanto totalmente gratuito, que ofrece grandes prestaciones para el análisis de datos de una forma además muy fácil de manejar. Son muchos los campos de la actividad humana donde es necesario utilizar Pandas, pero es en concreto en el ámbito de machine learning, donde junto a numpy ofrece grandes prestaciones.
Es indudable que un paquete con las prestaciones que ofrece Pandas es imposible de abordar y de manejar dentro de la limitación que ofrece un post, por este motivo en lo que sigue se mostrarán unas pocas características del paquete, y se deja al lector interesado que acuda a este enlace para que pueda adquirir en su total amplitud las posibilidades que ofrece Pandas.
La instalación de Pandas dentro de Python es sumamente fácil. Simplemente con introducir la siguiente instrucción en la pantalla de comandos de windows pip install pandas ya se tendría Pandas lista para poder ser utilizado y poder trabajar con él.
Este paquete posee básicamente tres estructuras de datos:
- Series. Utilizadas en estructuras de datos con dimensión 1.
- DataFrame. Utilizado en estructuras de datos con dimensión 2.
- Panel. Utilizado en estructuras de datos con dimensión 3.
En Pandas, los datos contenido dentro de una Serie son inmutables ( no se pueden cambiar ), pero los datos almacenados en Dataframes o de tipo Panel son mutables, es decir se pueden cambiar en el proceso de trabajo con los datos.
Datos de tipo Series
Como ya hemos comentado anteriormente, este tipo de datos son estructuras unidimensionales de tipo inmutable que pueden contener datos de cualquier tipo ( enteros, caracteres, float, objetos de tipo Python, etc. ).
Un constructor utilizado para obtener este tipo de estructuras, puede ser el que se muestra a continuación:
pandas.Series(data=None, index=None, dtype=None, name=None, copy=False, fastpath=False)
Los parámetros que vemos en el constructor significan los siguiente:
- data. Puede ser un np.array, una lista o constantes.
- index. Debe ser un conjunto de valores no repetidos.
- dtype. Es el tipo de datos con el que se rabaja.
- copy. Para copiar o no los datos. El valor por defecto es False.
Este tipo de datos se puede crear desde: un np.array, un diccionario o valores escalares.
Veamos a continuación cómo crear este tipo de datos:
#Primero importamos la libreria y decimos que nos referimos a ella con pd
import pandas as pd
s=pd.Series()
print(s)
#Vemos nos devuelve un objeto vacío con el tipo de datos por defecto float64
Series([], dtype: float64)
Crearemos a un objeto Series, partiendo de un numpy.array
import pandas as pd
#Importamos la librería numpy que también es muy usada en machine learning
import numpy as np
data=np.array(['Pedro','Juan','Marisa','Ferdinand'])
#Ahora creamos datos tipo Series
datos= pd.Series(data)
print(datos)
#Observemos la primera columna que se obtiene, es el índice que por defecto se crea
0 Pedro
1 Juan
2 Marisa
3 Ferdinand
dtype: object
Ahora creamos un objeto similar al anterior, pero con un índice diferente.
data=np.array(['Pedro','Juan','Marisa','Ferdinand'])
#Ahora creamos datos tipo Series pero con un deteminado índice
datos= pd.Series(data,index=[20,21,22,23])
print(datos)
20 Pedro
21 Juan
22 Marisa
23 Ferdinand
dtype: object
Como ya se ha dicho en apartados anteriores, también se puede crear este tipo de datos utilizando un objeto de Python denominado diccionario. En este caso las claves del diccionario, se utilizan para crear el índice y los valores, serían los valores del objeto series que se está creando.
import pandas as pd
import numpy as np
datos={'unos':1,'dos':2,'tres':3,'cuatro':4}
s=pd.Series(datos)
print(s)
cuatro 4
dos 2
tres 3
unos 1
dtype: int64
Por último y para concluir la presentación de la creación de Serie, veamos un ejemplo de cómo generar este tipo de datos mediante la utilización de un escalar.
import pandas as pd
datos=pd.Series(5,index=([3,6,7,9]))
print(datos)
3 5
6 5
7 5
9 5
dtype: int64
Obteniendo datos de Series
En los apartados anteriores hemos podido ver cómo crear elementos del tipo Series, ahora ya estaríamos en condiciones para poder extraer la información que previamente se ha almacenado. Para conseguir esto existen diferentes formas que a continuación se pasan a exponer con los ejemplos que se presentan.
# Primero elaboramos los datos.
import pandas as pd
datos=pd.Series([3,6,2,3,5,7,2,4],index=(["uno","dos","tres","cuatro","cinco",
"seis","siete","ocho"]))
print("Extraemos el primer elemento: ",datos[0])
print("Extraemos el tercer elemento:",datos[2])
print("Extraemos los cuatro primeros elementos:\n",datos[:4])
print("Extraemos los dos elementos por la derecha: \n",datos[-2:])
print("Uso del index para extraer elementos: \n", datos["dos"])
print("Saco varios elementos con el index: \n",datos[["dos","cuatro"]])
Extraemos el primer elemento: 3
Extraemos el tercer elemento: 2
Extraemos los cuatro primeros elementos:
uno 3
dos 6
tres 2
cuatro 3
dtype: int64
Extraemos los dos elementos por la derecha:
siete 2
ocho 4
dtype: int64
Uso del index para extraer elementos:
6
Saco varios elementos con el index:
dos 6
cuatro 3
dtype: int64
Datos de tipo DataFrame
Como ya se ha dicho anteriormente, este tipo de datos tiene una estructura tabular y organiza los datos en un conjunto de filas y columnas. Este tipo de datos es mutable y por lo tanto admite cambios, así como etiquetas para denominar a sus filas o columnas.
De acuerdo en el API que regula este tipo de datos, su constructor tiene el siguiente formato:
DataFrame([data, index, columns, dtype, copy])
Donde el significado de los parámetros es similar a lo comentado en el apartado anterior.
Este tipo de datos se puede construir utilizando como input datos del tipo:
- Listas
- Diccionarios
- Series
- Numpy arrays
- Otros DataFrame
A continuación podemos ver cómo construir un DataFrame vacío.
import pandas as pd
datos=pd.DataFrame()
print(datos)
Empty DataFrame
Columns: []
Index: []
Creamos un DataFrame desde una lista de elementos
import pandas as pd
d=[3,5,2,6,3,5,8]
datos=pd.DataFrame(d)
print(datos)
#Obtenemos algún tipo de información utilizando algún atributo
print("La media seria: ", datos.mean())
print("El número de elementos, serían: ", datos.count())
print("La suma acumuada es: ", datos.cumsum())
0
0 3
1 5
2 2
3 6
4 3
5 5
6 8
La media seria: 0 4.571429
dtype: float64
El número de elementos, serían: 0 7
dtype: int64
La suma acumuada es: 0
0 3
1 8
2 10
3 16
4 19
5 24
6 32
Crearemos a continuación un DataFrame con dos columnas de la siguiente manera.
import pandas as pd
#Generamos una lista de elementos
d=[["Luis",35],["Maria",24],["Fernando",45],["Mercedes",27]]
print("Tipo datos d:",type(d))
datos=pd.DataFrame(d,columns=["Nombre","Edad"],dtype=float)
print(datos)
# Ahora los datos serían enteros
print("\n Si queremos trabajar con datos de tipo entero \n")
datos2=pd.DataFrame(d,columns=["Nombre","Edad"],dtype=int)
print(datos2)
print("\n Los tipos de datos serían:")
datos2.dtypes
Tipo datos d: <class 'list'>
Nombre Edad
0 luis 35.0
1 Maria 24.0
2 Fernando 45.0
3 Mercedes 27.0
Si queremos trabajar con datos de tipo entero
Nombre Edad
0 luis 35
1 Maria 24
2 Fernando 45
3 Mercedes 27
Los tipos de datos serían:
Nombre object
Edad int32
dtype: object
Hagamos lo mismo que antes pero utilizando un diccionario que contiene listas o np.array-
import pandas as pd
d={'Nombre':['Luis','Maria','Fernando','Mercedes'],'Edad':[35,24,45,27]}
datos=pd.DataFrame(d)
print(datos)
Edad Nombre
0 35 Luis
1 24 Maria
2 45 Fernando
3 27 Mercedes
Igualmente se puede construir un DataFrame vía una lista de diccionarios, en el siguiente ejemplo se indica cómo hacerlo.
#Como pandas ya lo tenemos cargado de celdas anteriores, no es necesario
#hacerlo aquí, pero a efectos didácticos se incluye de nuevo
import pandas as pd
d=[{'Nombre':'luis','Edad':35},{'Nombre':'Maria','Edad':24},{'Nombre':'Fernando','Edad':45},
{'Nombre':'Mercedea','Edad':27}]
datos=pd.DataFrame(d)
print(datos)
Edad Nombre
0 35 luis
1 24 Maria
2 45 Fernando
3 27 Mercedea
Veamos a continuación un ejemplo de construcción de un DataFrame, utilizando para ello un diccionario de Series.
d={
'primero':pd.Series([2,4,3,7],index=['a1','a2','a3','a4']),
'segundo':pd.Series([4,2,7,9,2],index=['a1','a2','a3','a4','a5'])
}
datos=pd.DataFrame(d)
print(datos)
primero segundo
a1 2.0 4
a2 4.0 2
a3 3.0 7
a4 7.0 9
a5 NaN 2
Si del anterior DataFrame quisiéramos seleccionar alguna columna, se podría hacer de la siguiente manera.
datos['primero']
a1 2.0
a2 4.0
a3 3.0
a4 7.0
a5 NaN
Name: primero, dtype: float64
Si queremos borrar una columna del DataFrame anterior, se haría de la siguiente manera.
del datos['primero']
print(datos)
segundo
a1 4
a2 2
a3 7
a4 9
a5 2
Igualmente se puede borrar una columna, utilizando la propiedad pop. A continuación un ejemplo sobre cómo hacerlo.
d={
'primero':pd.Series([2,4,3,7],index=['a1','a2','a3','a4']),
'segundo':pd.Series([4,2,7,9,2],index=['a1','a2','a3','a4','a5'])
}
datos=pd.DataFrame(d)
datos.pop('primero')
print(datos)
segundo
a1 4
a2 2
a3 7
a4 9
a5 2
Para borrar filas, se utiliza la propiedad drop. Veamos cómo hacer en el ejemplo siguiente:
#Borramos filas 2 y 4
datos=datos.drop(['a2','a4'],axis=0)
print(datos)
segundo
a1 4
a3 7
a5 2
Datos de tipo Panel
Como ya se ha dicho esta estructura de datos se utiliza para datos estructurados en tres dimensiones.
En este tipo de estructuras, se dispone de una nomenclatura propia para hacer referencia a cada uno de los tres ejes con los que se trabaja. Esta nomenclatura es la siguiente:
- items: Hace referencia al eje 0. Cada uno de estos item’s hace referencia a un DataFrame que lo contiene.
- major_axis: Hace referencia al eje 1, son las filas de cada uno de los DataFrame con los que se trabaja.
- minor_axis: Hace referencia al eje 2, son las columnas de cada uno de los DataFrame con los que se trabaja.
El constructor de este tipo de objetos es el siguiente:
pandas.Panel(data=None, items=None, major_axis=None, minor_axis=None, copy=False, dtype=None)
El significado de cada uno de los parámetros es el ya comentado anteriormente, salvo los nuevos que se comentan a continuación:
- items. Los índices que corresponden al eje 0
- major_axis. Los índices que corresponden al eje 1
- minos_axis. Los índices que corresponden al eje 2
¿ Cómo crear un Panel ?
Para crear este tipo de datos, se puede utilizar:
- numpy arrays
- Diccionario de DataFrames
A continuación y a efectos meramente didácticos, se muestra cómo poder crear un Panel desde un numpy array que contiene números aleatorios.
import pandas as pd
import numpy as np
d= np.random.rand(3,2,4)
print("Tipo de d: ",type(d))
datos=pd.Panel(d)
print(datos)
Tipo de d: <class 'numpy.ndarray'>
<class 'pandas.core.panel.Panel'>
Dimensions: 3 (items) x 2 (major_axis) x 4 (minor_axis)
Items axis: 0 to 2
Major_axis axis: 0 to 1
Minor_axis axis: 0 to 3
Para construirlo desde un diccionario de objetos de tipo DataFrame, se haría de la siguiente manera:
d={
'uno':pd.DataFrame([1,3,5,7,8,5]),
'dos':pd.DataFrame([4,2,5,6,7,8]),
'tres':pd.DataFrame([4,1,6,3,7,2])
}
datos=pd.Panel(d)
print(datos)
<class 'pandas.core.panel.Panel'>
Dimensions: 3 (items) x 6 (major_axis) x 1 (minor_axis)
Items axis: dos to uno
Major_axis axis: 0 to 5
Minor_axis axis: 0 to 0
Seleccionar datos de un Panel
La forma de seleccionar datos de una estructura de datos de tipo Panel, es similar a como se ha hecho con otros objetos, pero dado que aquí se está trabajando con tres dimensiones, presenta ciertas peculiaridades que se pretenden aclarar con los siguientes ejemplos:
a=datos['uno']
print("Tipo de datos de a: ",type(a))
print(a)
Tipo de datos de a: <class 'pandas.core.frame.DataFrame'>
0
0 1
1 3
2 5
3 7
4 8
5 5
Para ver cómo hacer para seleccionara través de los ejes 2 y 3, vamos a crear un Panel con más datos que el construido anteriormente.
#establezco primero una semilla para sacar siempre el mismo resultado
np.random.seed(20)
d={
'uno':pd.DataFrame(np.random.randn(4,3)),
'dos':pd.DataFrame(np.random.randn(5,2))
}
datos=pd.Panel(d)
print(datos)
<class 'pandas.core.panel.Panel'>
Dimensions: 2 (items) x 5 (major_axis) x 3 (minor_axis)
Items axis: dos to uno
Major_axis axis: 0 to 4
Minor_axis axis: 0 to 2
print(datos['uno'],"\n")
print(datos['dos'],"\n")
0 1 2
0 0.883893 0.195865 0.357537
1 -2.343262 -1.084833 0.559696
2 0.939469 -0.978481 0.503097
3 0.406414 0.323461 -0.493411
4 NaN NaN NaN
0 1 2
0 -0.792017 -0.842368 NaN
1 -1.279503 0.245715 NaN
2 -0.044195 1.567633 NaN
3 1.051109 0.406368 NaN
4 -0.168646 -3.189703 NaN
#Saca la la segunda fila (con disposición de columna) de cada
#uno de los DataFrame con los que se trabaja
print(datos.major_xs(1) )
dos uno
0 -1.279503 -2.343262
1 0.245715 -1.084833
2 NaN 0.559696
#Sacaría la tercera columna de cada uno de los dos DataFrame anteriores
print(datos.minor_xs(2))
dos uno
0 NaN 0.357537
1 NaN 0.559696
2 NaN 0.503097
3 NaN -0.493411
4 NaN NaN
Trabajando con Pandas
Pandas cuenta con una amplia gama de funciones y propiedades para poder conseguir muchos objetivos. Debido a que todas esas funciones y propiedades es imposible abarcarlas en el presente post, a continuación se da indicación de donde poder encontrarla para cada uno de los tres objetos mostrados en párrafos anteriores.
- Para Serie: Click en este enlace
- Para DataFrame: Click en este enlace
- Para Panel: Click en este enlace
No obstante y a efectos meramente ilustrativos, a continuación se muestran algunos ejemplos sobre la forma de operar con estas funciones o propiedades.
Para realizar algunos ejemplos, vamos a utilizar el popular fichero denominado “Iris.csv”. Es un conjunto de datos que lo extraemos de https://archive.ics.uci.edu/ml/index.php. Para poder leer sus datos los hacemos con la instrucción:
pandas.read_csv(….)
En concreto la instrucción que se utilizará será la siguiente:
d=pd.read_csv("https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data",
names=['slength','swidth','plength','pwidth','tipo'],header=None )
Para ver los datos con los que estamos trabajando, podemos utilizar las propiedades head() y tail() que nos muestran tanto los datos iniciales como los finales
print(d.head(),"\n")
print(d.tail(),"\n")
print(type(d))
slength swidth plength pwidth tipo
0 5.1 3.5 1.4 0.2 Iris-setosa
1 4.9 3.0 1.4 0.2 Iris-setosa
2 4.7 3.2 1.3 0.2 Iris-setosa
3 4.6 3.1 1.5 0.2 Iris-setosa
4 5.0 3.6 1.4 0.2 Iris-setosa
slength swidth plength pwidth tipo
145 6.7 3.0 5.2 2.3 Iris-virginica
146 6.3 2.5 5.0 1.9 Iris-virginica
147 6.5 3.0 5.2 2.0 Iris-virginica
148 6.2 3.4 5.4 2.3 Iris-virginica
149 5.9 3.0 5.1 1.8 Iris-virginica
<class 'pandas.core.frame.DataFrame'>
#Con la propiedad describe() podemos sacar las estadísticas básicas de las columnas numéricas
d.describe()
| slength | swidth | plength | pwidth | |
|---|---|---|---|---|
| count | 150.000000 | 150.000000 | 150.000000 | 150.000000 |
| mean | 5.843333 | 3.054000 | 3.758667 | 1.198667 |
| std | 0.828066 | 0.433594 | 1.764420 | 0.763161 |
| min | 4.300000 | 2.000000 | 1.000000 | 0.100000 |
| 25% | 5.100000 | 2.800000 | 1.600000 | 0.300000 |
| 50% | 5.800000 | 3.000000 | 4.350000 | 1.300000 |
| 75% | 6.400000 | 3.300000 | 5.100000 | 1.800000 |
| max | 7.900000 | 4.400000 | 6.900000 | 2.500000 |
A continuación procedemos a calcular algunas propiedades útiles de los datos obtenidos
print("La correlación entre las columnas numéricas es: \n",d.corr())
La correlación entre las columnas numéricas es:
slength swidth plength pwidth
slength 1.000000 -0.109369 0.871754 0.817954
swidth -0.109369 1.000000 -0.420516 -0.356544
plength 0.871754 -0.420516 1.000000 0.962757
pwidth 0.817954 -0.356544 0.962757 1.000000
print("La covarianza entre las columnas numéricas es: \n",d.cov())
La covarianza entre las columnas numéricas es:
slength swidth plength pwidth
slength 0.685694 -0.039268 1.273682 0.516904
swidth -0.039268 0.188004 -0.321713 -0.117981
plength 1.273682 -0.321713 3.113179 1.296387
pwidth 0.516904 -0.117981 1.296387 0.582414
print("El máximo acumulado es: \n",d.cummax() )
El máximo acumulado es:
slength swidth plength pwidth tipo
0 5.1 3.5 1.4 0.2 Iris-setosa
1 5.1 3.5 1.4 0.2 Iris-setosa
2 5.1 3.5 1.4 0.2 Iris-setosa
3 5.1 3.5 1.5 0.2 Iris-setosa
4 5.1 3.6 1.5 0.2 Iris-setosa
5 5.4 3.9 1.7 0.4 Iris-setosa
6 5.4 3.9 1.7 0.4 Iris-setosa
7 5.4 3.9 1.7 0.4 Iris-setosa
8 5.4 3.9 1.7 0.4 Iris-setosa
9 5.4 3.9 1.7 0.4 Iris-setosa
10 5.4 3.9 1.7 0.4 Iris-setosa
11 5.4 3.9 1.7 0.4 Iris-setosa
12 5.4 3.9 1.7 0.4 Iris-setosa
13 5.4 3.9 1.7 0.4 Iris-setosa
14 5.8 4 1.7 0.4 Iris-setosa
15 5.8 4.4 1.7 0.4 Iris-setosa
16 5.8 4.4 1.7 0.4 Iris-setosa
17 5.8 4.4 1.7 0.4 Iris-setosa
18 5.8 4.4 1.7 0.4 Iris-setosa
19 5.8 4.4 1.7 0.4 Iris-setosa
20 5.8 4.4 1.7 0.4 Iris-setosa
21 5.8 4.4 1.7 0.4 Iris-setosa
22 5.8 4.4 1.7 0.4 Iris-setosa
23 5.8 4.4 1.7 0.5 Iris-setosa
24 5.8 4.4 1.9 0.5 Iris-setosa
25 5.8 4.4 1.9 0.5 Iris-setosa
26 5.8 4.4 1.9 0.5 Iris-setosa
27 5.8 4.4 1.9 0.5 Iris-setosa
28 5.8 4.4 1.9 0.5 Iris-setosa
29 5.8 4.4 1.9 0.5 Iris-setosa
.. ... ... ... ... ...
120 7.7 4.4 6.9 2.5 Iris-virginica
121 7.7 4.4 6.9 2.5 Iris-virginica
122 7.7 4.4 6.9 2.5 Iris-virginica
123 7.7 4.4 6.9 2.5 Iris-virginica
124 7.7 4.4 6.9 2.5 Iris-virginica
125 7.7 4.4 6.9 2.5 Iris-virginica
126 7.7 4.4 6.9 2.5 Iris-virginica
127 7.7 4.4 6.9 2.5 Iris-virginica
128 7.7 4.4 6.9 2.5 Iris-virginica
129 7.7 4.4 6.9 2.5 Iris-virginica
130 7.7 4.4 6.9 2.5 Iris-virginica
131 7.9 4.4 6.9 2.5 Iris-virginica
132 7.9 4.4 6.9 2.5 Iris-virginica
133 7.9 4.4 6.9 2.5 Iris-virginica
134 7.9 4.4 6.9 2.5 Iris-virginica
135 7.9 4.4 6.9 2.5 Iris-virginica
136 7.9 4.4 6.9 2.5 Iris-virginica
137 7.9 4.4 6.9 2.5 Iris-virginica
138 7.9 4.4 6.9 2.5 Iris-virginica
139 7.9 4.4 6.9 2.5 Iris-virginica
140 7.9 4.4 6.9 2.5 Iris-virginica
141 7.9 4.4 6.9 2.5 Iris-virginica
142 7.9 4.4 6.9 2.5 Iris-virginica
143 7.9 4.4 6.9 2.5 Iris-virginica
144 7.9 4.4 6.9 2.5 Iris-virginica
145 7.9 4.4 6.9 2.5 Iris-virginica
146 7.9 4.4 6.9 2.5 Iris-virginica
147 7.9 4.4 6.9 2.5 Iris-virginica
148 7.9 4.4 6.9 2.5 Iris-virginica
149 7.9 4.4 6.9 2.5 Iris-virginica
[150 rows x 5 columns]
Se puede calcular la kurtosis:
d.kurtosis()
slength -0.552064
swidth 0.290781
plength -1.401921
pwidth -1.339754
dtype: float64
Indexar y seleccionar datos
En apartados anteriores, se han presentados diversos formatos que Pandas ofrece para entresacar datos. Sin embargo existen ciertas herramientas que permiten entresacar esa información de una manera muchos más eficiente.
Para obtener estas facilidades Pandas ofrece tres tipos de indexación:
- .loc[ ]: Indexación basada en etiquetas.
- .iloc[ ] : Indexación basada en índices enteros.
- .ix[ ] : Indexación mezcla de los dos tipos anteriores.
A continuación se muestran ejemplos sobre cómo utilizar esos tipos de indexación, para ello en primer lugar vamos a crear un DataFrame sobre el que vamos a hacer las búsqedas.
import pandas as pd
import numpy as np
datos=pd.DataFrame(np.random.rand(7,4), columns=['a1','a2','a3','a4'])
datos.describe()
| a1 | a2 | a3 | a4 | |
|---|---|---|---|---|
| count | 7.000000 | 7.000000 | 7.000000 | 7.000000 |
| mean | 0.492404 | 0.405917 | 0.626874 | 0.616920 |
| std | 0.277903 | 0.364459 | 0.256695 | 0.270604 |
| min | 0.068853 | 0.023517 | 0.356625 | 0.104124 |
| 25% | 0.404503 | 0.156795 | 0.372480 | 0.546806 |
| 50% | 0.424355 | 0.338362 | 0.654432 | 0.664520 |
| 75% | 0.576624 | 0.602521 | 0.859492 | 0.738059 |
| max | 0.991365 | 0.960907 | 0.913114 | 0.980067 |
Indexación con .loc()
A continuación se muestran diferentes formas de hacer búsquedas mediante este sistema de indexación.
#Usando una sola columna, y varias filas.
print(datos.loc[1:3,'a1'])
1 0.068853
2 0.582508
3 0.570740
Name: a1, dtype: float64
# La misma búsqueda pero para dos columnas
datos.loc[1:3,['a1','a3']]
| a1 | a3 | |
|---|---|---|
| 1 | 0.068853 | 0.890016 |
| 2 | 0.582508 | 0.913114 |
| 3 | 0.570740 | 0.379810 |
#Si queremos ver sólo las tres primeras filas
datos.loc[1:3]
| a1 | a2 | a3 | a4 | |
|---|---|---|---|---|
| 1 | 0.068853 | 0.258993 | 0.890016 | 0.575058 |
| 2 | 0.582508 | 0.843205 | 0.913114 | 0.518553 |
| 3 | 0.570740 | 0.361836 | 0.379810 | 0.104124 |
También se pueden hacer extracciones de datos mediante vectores de tipo lógico. En primer lugar se muestra un ejemplo donde se puede ver cómo poder construir un objeto de tipo lógico.
datos.loc[:,'a1']>0.5
0 False
1 False
2 True
3 True
4 False
5 True
6 False
Name: a1, dtype: bool
Construido el objeto de tipo lógico, se puede usar para hacer selecciones de datos. En el ejemplo que sigue, se van a seleccionar las filas que tienen el valor “True” en el resultado anterior ( en total tres filas ).
a=datos.loc[:,'a1']>0.5
print(datos.loc[a] )
a1 a2 a3 a4
2 0.582508 0.843205 0.913114 0.518553
3 0.570740 0.361836 0.379810 0.104124
5 0.991365 0.054597 0.828968 0.765267
Indexación con .iloc()
En este caso se trata de una búsqueda mediante indicadores enteros de la posición de los elementos. Para hacer este tipo de búsqueda, se puede utilizar:
- Un entero
- Una lista de enteros
- Un rango de valores
Veamos unos ejemplo sobre su uso, en base a ejemplos utilizando el conjunto de datos obtenido anteriormente.
# Seleccionamos las primeras filas y todas las columnas
datos.iloc[:3]
| a1 | a2 | a3 | a4 | |
|---|---|---|---|---|
| 0 | 0.424355 | 0.960907 | 0.654432 | 0.980067 |
| 1 | 0.068853 | 0.258993 | 0.890016 | 0.575058 |
| 2 | 0.582508 | 0.843205 | 0.913114 | 0.518553 |
#Seleccionamos ciertas filas y columnas
datos.iloc[:3,1:3]
| a2 | a3 | |
|---|---|---|
| 0 | 0.960907 | 0.654432 |
| 1 | 0.258993 | 0.890016 |
| 2 | 0.843205 | 0.913114 |
#Indicamos la lista de filas y columnas
datos.iloc[[1,3],[0,1,3]]
| a1 | a2 | a4 | |
|---|---|---|---|
| 1 | 0.068853 | 0.258993 | 0.575058 |
| 3 | 0.570740 | 0.361836 | 0.104124 |
Indexación con .ix()
Se trata de un sistema de selección que es una mezcla de los dos anteriores, es decir se hace selección por etiquetas y por enteros. Veamos algún ejemplo.Como vemos es un método que está en desuso, pero que con la versión con la que se está trabajando aún se puede utilizar. Ahora bien en versiones posteriores desaparecerá.
datos.ix[1:2,['a1','a2']]
D:\programas\Anaconda\lib\site-packages\ipykernel_launcher.py:1: DeprecationWarning:
.ix is deprecated. Please use
.loc for label based indexing or
.iloc for positional indexing
See the documentation here:
http://pandas.pydata.org/pandas-docs/stable/indexing.html#ix-indexer-is-deprecated
"""Entry point for launching an IPython kernel.
| a1 | a2 | |
|---|---|---|
| 1 | 0.068853 | 0.258993 |
| 2 | 0.582508 | 0.843205 |
Pipeline en Pandas
Con Pandas también se pueden enlazar resultados, es decir se puede hacer pipeline que agiliza enormemente el trabajo. A continuación se muestra un ejemplo. Inicialmente creamos el DataFrama con el que vamos a trabajar.
import pandas as pd
# Creamos un DataFrame vacío
df = pd.DataFrame()
# Creams una serie de columnas
df['nombre'] = ['Francisco', 'Maria', 'Sara','Fernando']
df['sexo'] = ['Varon', 'Mujer', 'Mujer','Varon']
df['edad'] = [31, 32, 19,54]
# Vemos el DataFrame
df
| nombre | sexo | edad | |
|---|---|---|---|
| 0 | Francisco | Varon | 31 |
| 1 | Maria | Mujer | 32 |
| 2 | Sara | Mujer | 19 |
| 3 | Fernando | Varon | 54 |
Creamos las funciones para posteriormente procesar con ellas los datos
# Creamos una función para calcular la media de datos agrupados
def media_grupo(dataframe, col):
# Agrupamos los datos de una columna y luego calculamos la media.
return dataframe.groupby(col).mean()
# Creamos una función que cambia a mayúsculas los nombres de las columnas
def mayusculas_columnas(dataframe):
# Pone mayúsculas los nombres de las columnas
dataframe.columns = dataframe.columns.str.upper()
# Y decuelve el resultado
return dataframe
Con ayuda de las funciones anteriores creamos ahora el pipeline
# Creamos un pipeline que calcula la media para cada sexo
(df.pipe(media_grupo, col='sexo')
# Despues pasamos a mayusculas el nombre de las columnas
.pipe(mayusculas_columnas)
)
| EDAD | |
|---|---|
| sexo | |
| Mujer | 25.5 |
| Varon | 42.5 |
Propiedad GroupBy
Con la propiedad GroupBy se pueden agrupar los datos por el valor de una variable categórica y sobre esa agrupación hacer operaciones tales como calcular la media en cada grupo, dividir los datos en esos grupo, etc. En lo que sigue vamos a ver cómo poder operar con esta propiedad para ello vamos a seguir con el dataset denominado “df” que hemos generado anteriormente:
print(df.groupby('sexo'))
#Observamos que esta instrucción no facilita mucha información
<pandas.core.groupby.DataFrameGroupBy object at 0x000001108F76E2E8>
#Sin embargo esta otra instrucción nos da mas información
#sobre los grupos generados
print(df.groupby('sexo').groups )
{'Mujer': Int64Index([1, 2], dtype='int64'), 'Varon': Int64Index([0, 3], dtype='int64')}
Si en lugar de una columna, quisiéramos hacer una partición de los datos por dos o más columnas, la instrucción a utilizar sería similar a la siguiente:
df.groupby(‘col1’,’col2’)
Se puede iterar sobre los grupos generados. Se obtendría el código del grupo y el nombre del grupo. En nuestro caso, los datos que se obtendrían serían los siguientes:
for nombre,grupo in df.groupby('sexo'):
print("El nombre es: ", nombre, "y el grupo es: \n",grupo )
El nombre es: Mujer y el grupo es:
nombre sexo edad
1 Maria Mujer 32
2 Sara Mujer 19
El nombre es: Varon y el grupo es:
nombre sexo edad
0 Francisco Varon 31
3 Fernando Varon 54
Se puede seleccionar un determinado grupo utilizando para ello el método get_group(). Veamos un ejemplo
agrupacion=df.groupby('sexo')
varones=agrupacion.get_group('Varon')
print(varones)
nombre sexo edad
0 Francisco Varon 31
3 Fernando Varon 54
Una vez hecha la partición de los datos por una o dos columnas, se pueden calcular datos agregados de una determinada variable, para cada una de las particiones obtenidas, veamos cómo.
import numpy as np
agrupacion=df.groupby('sexo')
print("La edad media para cada sexo es: ")
print(agrupacion['edad'].agg(np.mean) )
print("El tamaño de cada grupo es: ")
print(agrupacion['edad'].agg(np.size) )
print("\n Para hacer varias agregaciones de una sola vez: \n")
print(agrupacion['edad'].agg([np.max,np.min,np.std]) )
La edad media para cada sexo es:
sexo
Mujer 25.5
Varon 42.5
Name: edad, dtype: float64
El tamaño de cada grupo es:
sexo
Mujer 2
Varon 2
Name: edad, dtype: int64
Para hacer varias agregaciones de una sola vez:
amax amin std
sexo
Mujer 32 19 9.192388
Varon 54 31 16.263456
Se pueden hacer transformaciones de los datos en cada uno de los grupos. Por ejemplo si queremos estandarizar los datos para cada uno de los grupos, se podría hacer de la siguiente manera.
agrupacion=df.groupby('sexo')
score = lambda x: (x - x.mean()) / x.std()*10
#Aplico la función anterior a cada uno de los grupos
print(agrupacion.transform(score))
edad
0 -7.071068
1 7.071068
2 -7.071068
3 7.071068
Gráficos con Pandas
Pandas permite generar gráficos comunes utilizados en data mining de una forma fácil y rápida. Se pueden hacer gráficos con datos de tipo Series y DataFrame. En este post me centraré en explicar cómo hacerlo con estructuras del tipo DataFrame, ya que con Series el procedimiento es análogo.
El constructor para la generación de gráficos con DataFrame es el siguiente:
DataFrame.plot(x=None, y=None, kind=’line’, ax=None, subplots=False, sharex=None, sharey=False, layout=None, figsize=None, use_index=True, title=None, grid=None, legend=True, style=None, logx=False, logy=False, loglog=False, xticks=None, yticks=None, xlim=None, ylim=None, rot=None, fontsize=None, colormap=None, table=False, yerr=None, xerr=None, secondary_y=False, sort_columns=False, **kwds)
Para ver la analogía a continuación se muestra el constructor para datos de dipo Series
Series.plot(kind=’line’, ax=None, figsize=None, use_index=True, title=None, grid=None, legend=False, style=None, logx=False, logy=False, loglog=False, xticks=None, yticks=None, xlim=None, ylim=None, rot=None, fontsize=None, colormap=None, table=False, yerr=None, xerr=None, label=None, secondary_y=False, **kwds)
El significado de cada uno de los parámetros se puede ver en la documentación de Pandas, no obstante conviene matizar el significado del parámetro “kind” que va a indicar el tipo de gráfico que quiere obtenerse. Los valores que puede tener, junto a su significado, se detallan a continuación:
- line: Para hacer gráficos de líneas (valor por defecto).
- bar: Para hacer gráficos de barras.
- barh: Para hacer gráficos de barras horizontales.
- hist: Para hacer histogramas.
- box: Para generar gráficos boxplot.
- kde: Para generar gráfico de estimación de la densidad.
- density: Igual que kde.
- area: Para generar un gráfico de áreas
- pie: Para generar un pie chart
- scatter: Para generar un gráfico de tipo scatter plot
- hexbin: para generar un hexbin plot
Además para cada uno de los tipos de gráficos mencionados arriba existen métodos concretos, que en el caso del un gráfico de areas, por poner un ejemplo, tendría el siguiente formato:
DataFrame.plot.area(x=None, y=None, **kwds)
Veamos a continuación algunos ejemplos que aclaren la operativa de estos comandos. En primer lugar, leemos un fichero con formato CSV y lo cargamos en la variables “datos”. Para leer este fichero utilizamos determinados parámetros, que a continuación se pasan a explicar:
- header=None. Para indicar que el fichero original no tiene cabecera con el nombre de las variables
- names=column_names. Para indicar que los campos están separados por blancos.
- na_values=’?’. Para indicar que los valores faltantes están indicados por ?.
- dtype={‘marca’:str}. Para indicar que la columna “marca” es de tipo carácter.
import pandas as pd
column_names = ['mpg', 'cilindros', 'desplazamiento', 'potencia', 'peso',
'aceleracion', 'ano', 'origen', 'marca']
datos=pd.read_csv("http://mlr.cs.umass.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data",
delim_whitespace=True,header=None, names=column_names,na_values='?',
dtype={'marca':str})
datos.head()
| mpg | cilindros | desplazamiento | potencia | peso | aceleracion | ano | origen | marca | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 18.0 | 8 | 307.0 | 130.0 | 3504.0 | 12.0 | 70 | 1 | chevrolet chevelle malibu |
| 1 | 15.0 | 8 | 350.0 | 165.0 | 3693.0 | 11.5 | 70 | 1 | buick skylark 320 |
| 2 | 18.0 | 8 | 318.0 | 150.0 | 3436.0 | 11.0 | 70 | 1 | plymouth satellite |
| 3 | 16.0 | 8 | 304.0 | 150.0 | 3433.0 | 12.0 | 70 | 1 | amc rebel sst |
| 4 | 17.0 | 8 | 302.0 | 140.0 | 3449.0 | 10.5 | 70 | 1 | ford torino |
# Vemos los tipos de datos con los que estamos trabajando
datos.dtypes
mpg float64
cilindros int64
desplazamiento float64
potencia float64
peso float64
aceleracion float64
ano int64
origen int64
marca object
dtype: object
#Para las variables numéricas sacamos los estadísticos
#más representativos
datos.describe()
| mpg | cilindros | desplazamiento | potencia | peso | aceleracion | ano | origen | |
|---|---|---|---|---|---|---|---|---|
| count | 398.000000 | 398.000000 | 398.000000 | 392.000000 | 398.000000 | 398.000000 | 398.000000 | 398.000000 |
| mean | 23.514573 | 5.454774 | 193.425879 | 104.469388 | 2970.424623 | 15.568090 | 76.010050 | 1.572864 |
| std | 7.815984 | 1.701004 | 104.269838 | 38.491160 | 846.841774 | 2.757689 | 3.697627 | 0.802055 |
| min | 9.000000 | 3.000000 | 68.000000 | 46.000000 | 1613.000000 | 8.000000 | 70.000000 | 1.000000 |
| 25% | 17.500000 | 4.000000 | 104.250000 | 75.000000 | 2223.750000 | 13.825000 | 73.000000 | 1.000000 |
| 50% | 23.000000 | 4.000000 | 148.500000 | 93.500000 | 2803.500000 | 15.500000 | 76.000000 | 1.000000 |
| 75% | 29.000000 | 8.000000 | 262.000000 | 126.000000 | 3608.000000 | 17.175000 | 79.000000 | 2.000000 |
| max | 46.600000 | 8.000000 | 455.000000 | 230.000000 | 5140.000000 | 24.800000 | 82.000000 | 3.000000 |
La funcionalidad de Pandas de generar gráficas, no es más que un envoltorio sobre la libreria “matplotlib” de python para generar gráficos.
Un primer gráfico explicativo de esta funcionalidad, es el que se puede conseguir con los siguientes instrucciones.
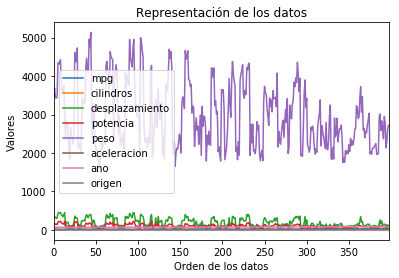
import matplotlib.pyplot as plt
%matplotlib inline
#Para ver la visualización en cuanto de genere el gráfico
img=datos.plot()
plt.title("Representación de los datos")
plt.xlabel("Orden de los datos")
plt.ylabel("Valores")
<matplotlib.text.Text at 0x1250d908>
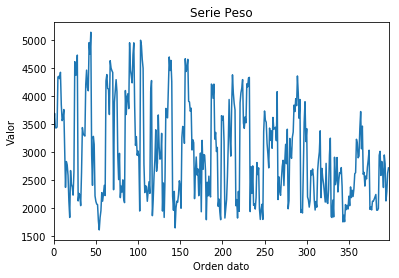
#Si queremos seleccionar alguna columna
img=datos.loc[:,"peso"].plot(title="Serie Peso" )
# datos.loc devuelve un objeto de tipo axis...
img.set_xlabel("Orden dato")
img.set_ylabel("Valor")
<matplotlib.text.Text at 0x12229630>
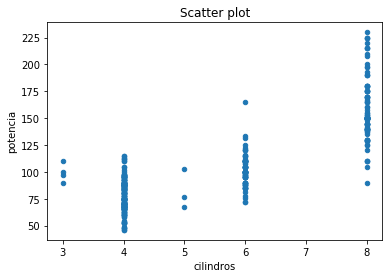
#Para un diagrama de barras
datos.plot(title="Scatter plot", kind='scatter',x='cilindros',y='potencia')
<matplotlib.axes._subplots.AxesSubplot at 0x148055c0>
import numpy as np
datos.groupby('cilindros').agg(np.size)
| mpg | desplazamiento | potencia | peso | aceleracion | ano | origen | marca | |
|---|---|---|---|---|---|---|---|---|
| cilindros | ||||||||
| 3 | 4.0 | 4.0 | 4.0 | 4.0 | 4.0 | 4 | 4 | 4 |
| 4 | 204.0 | 204.0 | 204.0 | 204.0 | 204.0 | 204 | 204 | 204 |
| 5 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3 | 3 | 3 |
| 6 | 84.0 | 84.0 | 84.0 | 84.0 | 84.0 | 84 | 84 | 84 |
| 8 | 103.0 | 103.0 | 103.0 | 103.0 | 103.0 | 103 | 103 | 103 |
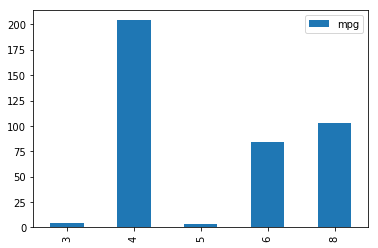
a=datos.groupby('cilindros').agg(np.size)
print(a.columns.values)
print(a.index.values)
#a.plot(x=cilindros,y=mpg,kind='bar')
['mpg' 'desplazamiento' 'potencia' 'peso' 'aceleracion' 'ano' 'origen'
'marca']
[3 4 5 6 8]
a.plot(x=a.index.values,y="mpg",kind='bar')
<matplotlib.axes._subplots.AxesSubplot at 0x14f78e48>
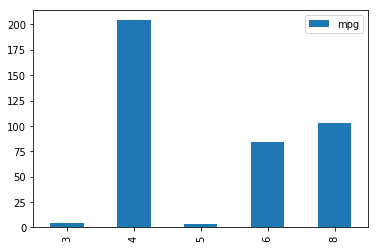
El gráfico anterior también se podría haber conseguido de la siguiente manera.
a.plot.bar(x=a.index.values,y="mpg")
<matplotlib.axes._subplots.AxesSubplot at 0x15037320>