OpenTSDB
Contenido
Introducción
La tecnología mapreduce que descansa sobre Hadoop ha permitido desarrollar muchas herramientas dentro el mundo “BigData” para el tratamiento de datos masivos. Muchas de estas tecnología se engloban dentro del denominado ecosistema de Hadoop que facilitan mucho la labor dentro del apartado del tratamiento masivo de la información.
La base sobre la que se sustenta OpenTSDB es un Time Series Daemon ( TSD ) que permite ofrecer toda la información que presentan el sistema. La interacción con este sistema se realiza mediante estos TSD, de tal manera que cada uno de los TSD con los que se trabaja en un momento determinado son independientes entre ellos, además hay que tener en cuenta que cada uno de estos TSD, trabajan contra la base de datos HBASE del ecosistema de Hadoop, por lo que es imprescindible tener levantada esta base. Existen tres métodos para poderse comunicar el usuario con los TSD:
1.- El protocolo telnet.
2.- Mediante el API HTML.
3.- Mediante unos sencillos comandos diseñados al efecto.
Arquitectura
El esquema gráfico sobre el que sustenta todo este sistema de puede ver en la siguiente figura.
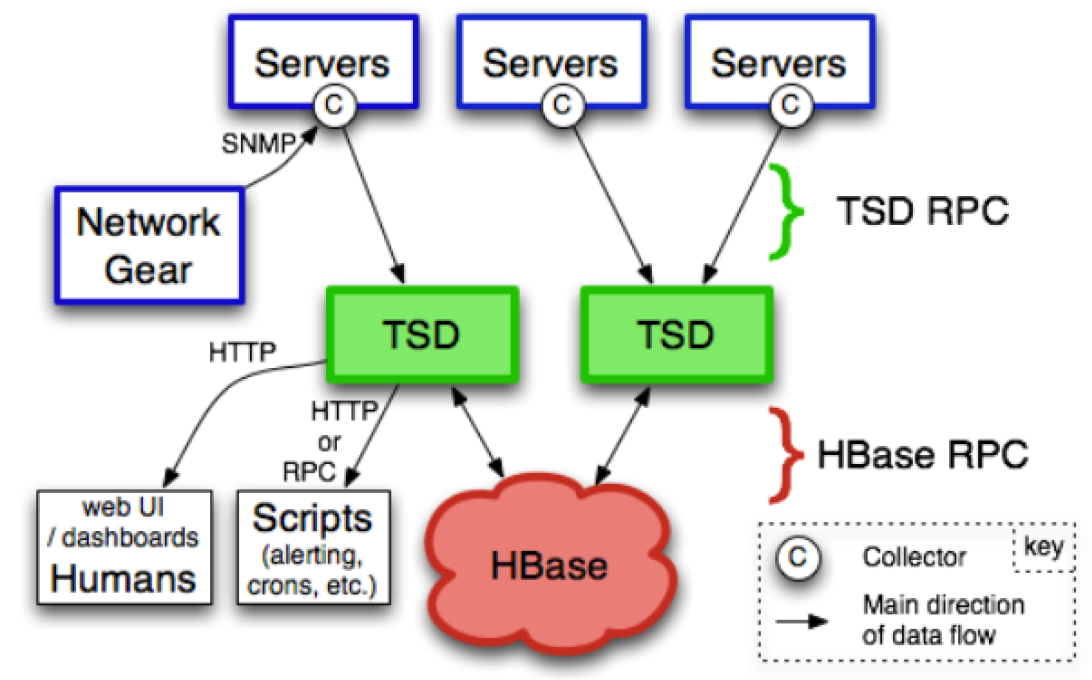
En OpenTSDB cada registro de la base de datos se denomina data point y la estructura del mismo se muestra en la siguiente figura :
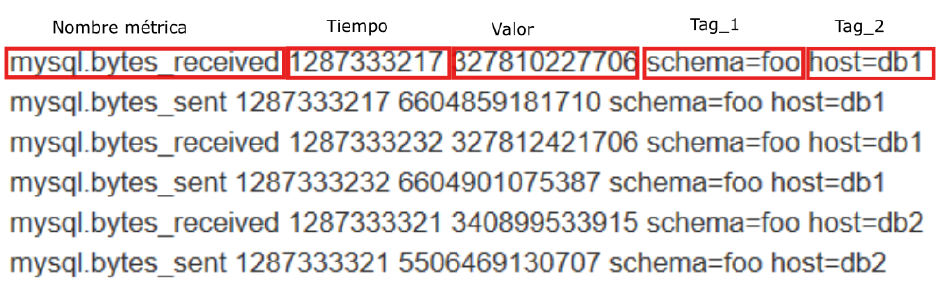
A continuación se detalla esa estructura:
1.- La primera parte sería el nombre de la métrica que se re eja en el registro.
2.- La segunda parte hace referencia al momento en el que se hace la medición. Este tiempo tiene una estructura UNIX y representa el tiempo en segundos o mili segundos desde el 1 de enero de 1970.
3.- A continuación vendría el valor tomado.
4.- Después vienes los “tags” o etiquetas que no son más que pares del tipo clave-valor.
OpenTSDB ofrece un diseño propio para poder ver los datos de cada serie temporal que se quiera seleccionar, y en este sentido ofrece una interfac gráfica donde se van a poder representar los datos que se deseen.
Características principales de OpenTSDB.
Entre las características que distinguen a esta base de datos se encuentran las siguientes:
1.- Los datos se almacenan con una precisión de hasta milisegundos.
2.- Se ejecuta sobre Hadoop y Hbase.
3.- Es perfectamente escalable y se adapta perfectamente a la inclusión de nuevos nodos en el cluster en el que trabaja.
El lector interesado, puede encontrar mucha más información en la página web del producto. O también si lo prefieres el autor de este blog ha elaborado un manual en castellano, con las instrucciones detalladas y pertinentes para que se pueda aprender el funcionamiento del OpenTSD desde un portátil. El documento lo tienes de forma gratuita haciendo click en este enlace, de agradecer es que pudieras *hacer alguna aportación totalmente voluntaria, al menos para reconocer mi esfuerzo por el desarrollo y mantenimiento de este blog, para ello no tienen más que hacer click en el botón “donate” que figura más abajo.
Igualmente cualquier comentario sobre estos temas son de agradecer, pues los mismos enriquecen aún más el contenido de este blog.